
A few years removed from the peak of the pandemic, we’re still understanding COVID-19’s impact on daily life. But one thing is certain – the pandemic made clear the importance of collecting and sharing health data.
The virus’ unpredictable and widespread nature made tracing and testing critical to understanding transmission and treatment. And it wasn’t limited to those in the healthcare and life sciences field – we relied on that information to guide our interactions with friends and family. Yet, this process also posed a credible threat to personal health data. With data being collected and shared around the world, millions of individual records were – and still are – at stake.
According to HIPAA, data sets meet compliance standards if there is a “very small” risk that individuals can be identified from the data. History has shown, however, that health data is easy to re-identify if not adequately protected. What measures can data teams implement to reduce the risk, particularly when the need is so urgent?
k-Anonymization, when combined with other straightforward techniques, is an effective way to enhance data security, regardless of industry. Now, it’s more dynamic and easy to apply, so you can defend against re-identification, accelerate speed to insights, and take action on crises like COVID-19.
What Is k-Anonymization?
Put simply, k-anonymization reduces re-identification risk by anonymizing indirect identifiers, thereby destroying the signal of data. It’s the data equivalent of hiding in a crowd; the more people — or in this case, data points — that are present and generally similar, the harder it is to pick out the details that can identify individuals.
K represents instances of tuples in a data set. A data set is k-anonymous when attributes within it are generalized or suppressed until each row is identical to at least k-1 other rows. Therefore, the higher the value of k, the lower the re-identification risk. Just as a larger crowd reduces the chance that you’ll find exactly who you’re looking for, k-anonymization works particularly well with large data sets.
However, if there isn’t enough data to anonymize indirect identifiers, lines of data may have to be redacted, making them unusable. Researchers therefore walk a fine line between privacy and utility, but one that is necessary from a legal and ethical standpoint.
Why Is k-Anonymization Critical When Handling Sensitive Data?
There are many different types of privacy enhancing technologies (PETs) that can be implemented to protect sensitive data, so what makes k-anonymization particularly effective? Let’s look at k-anonymization using COVID-19 research as an example.
Say researchers gather data that includes individuals’ names, locations, genders, ages, and virus diagnoses — information that could help local health departments track cases, anticipate high risk individuals, and allocate testing resources. Sharing that raw data set would be a far cry from satisfying HIPAA’s “very small” re-identification risk, not to mention that it could also open the door for issues down the line, such as insurance or rent discrimination.
Even if names — a direct identifier — were masked, it’s easy to derive a patient’s identity from the remaining information. In fact, Harvard professor Latanya Sweeney found that an alarming 87% of the population can be re-identified based on just their birth date, gender, and zip code. In theory, a health clinic employee familiar with each patient and who has access to their basic personal information, like address and birthday, could reasonably match a patient with a positive or negative COVID-19 test. And, since we must always assume a highly motivated and/or knowledgeable attacker exists, it’s safe to call this a high risk, high feasibility situation.
The question then becomes, how do you anonymize the other data columns without losing the data set’s integrity or usability? This is where it’s easy to see why sensitive data like PHI requires more comprehensive privacy controls — but also ones that won’t completely sacrifice utility for privacy. Let’s look at how k-anonymization strikes the balance.
What Is an Example of k-Anonymization In Practice?
To illustrate how k-anonymization works in practice, we’ll draw on our COVID-19 “data set.” Recall that researchers have patients’ names, locations, genders, ages, and COVID-19 diagnoses. Next, they must identify the most important data for their needs — in this case, the patients’ diagnoses. The diagnoses, along with patients’ names, are direct identifiers; however, the names aren’t critical to the research goal, and therefore can be masked. The remaining data are all indirect identifiers that could be combined with other data to reveal a patient’s identity, so must be generalized or suppressed in order to mitigate risk of re-identification.
A data set’s risk level is dependent on its most at-risk individual. That means if a single patient has a different location, gender, or age than every other patient, there is a 100% risk of re-identification. Let’s say of three females in the data set, only one is from a certain city. Researchers can suppress gender so that k=3, reducing re-identification risk to 33% — certainly a step in the right direction, but still well above the CMS standard of 9%.
To further reduce re-identification risk, researchers can work with the remaining indirect identifiers of location and age. Imagine in our data set that only one patient is 25-years-old, but several of the other individuals are 29. In this case, researchers can generalize the data by showing age ranges (i.e. ≤20, 21-30, ≥31). Depending on the ages of the other patients, this level of anonymization may be sufficient, or researchers may have to generalize or suppress locations.
If the re-identification probability is still deemed too high once all anonymization options have been exhausted, researchers’ final options are to add more rows or collect informed consent from the patients. Otherwise, they can’t legally or ethically share the data set. It quickly becomes easy to see why k-anonymization works best on larger data sets — but also how in the right data environment, it provides a high level of privacy and utility. When combined with other PETs, like randomized response and sampling, it can help protect data from collection to analysis.
Why Is Now the Time for k-Anonymization?
k-Anonymization is nothing new, but its practicality is. Custom coding and ETL processes have historically slowed the technique’s time-to-data and scalability. However, with Immuta’s plain language policy builder, it’s easy for technical and non-technical stakeholders to author, understand, and audit where and how k-anonymity is enforced. Immuta’s attribute-based access control (ABAC) model applies k-anonymization at query runtime on any data source across your organization — eliminating the manual, code-based, or ETL approaches. This enables you to rapidly derive value from any sensitive data without worrying about privacy concerns or data copies.
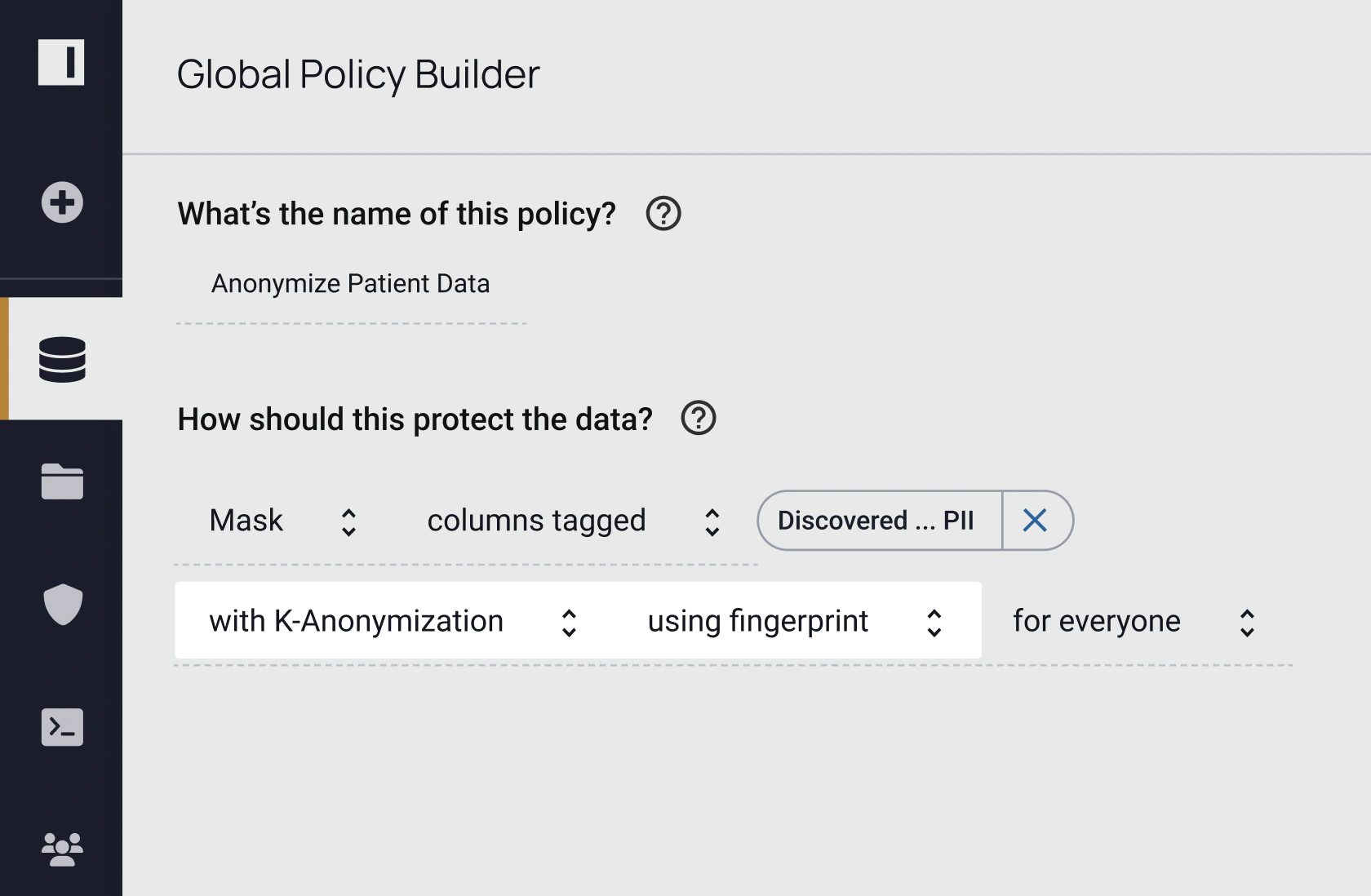
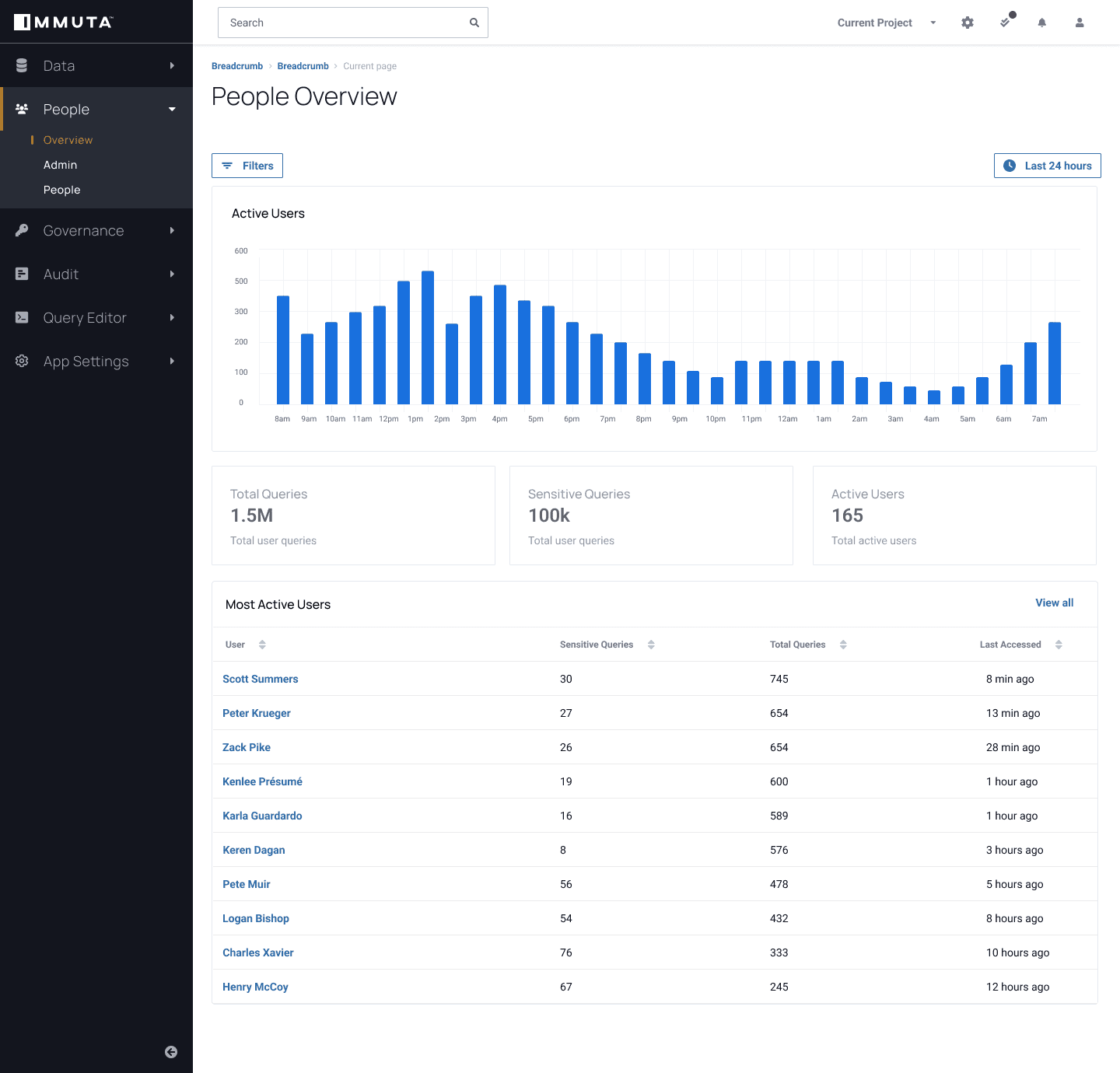
Immuta Detect also enables continuous data monitoring, so you can track queries on sensitive data and how that data is being used. This puts you in a better position to proactively track user behavior analytics and identify anomalies before they can become critical issues.
Data privacy can’t be sacrificed for speed, and without utility, data-driven decisions can’t be made. k-Anonymization can help transform, analyze, and share secure data at scale, making it an important privacy enhancing technology for modern data governance.
Don’t wait to start implementing PETs to protect your data. Learn how with our guide to Reducing Re-Identification Risk in Health Data.
Ready to see Immuta in action?


