
What Is a Data Mesh?
As Zhamak Dehghani describes in her original article, “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”: “[a Data Mesh] is the convergence of Distributed Domain Driven Architecture, Self-serve Platform Design, and Product Thinking with Data.”
What does that really mean? Rather than putting one team in charge of centralizing all data and making it valuable to the business, you instead allow different domains to own and create their own data products. Why? Just centralizing your data does nothing if you can’t use it to create data products that are useful to your business, and only people with domain-specific knowledge and expertise can be the product managers to create meaningful data products. To do so, they must own the creation of those data products, which means how the data is transformed into value.
The Data Mesh Architecture
Breaking the data mesh down logically, there are three key components:
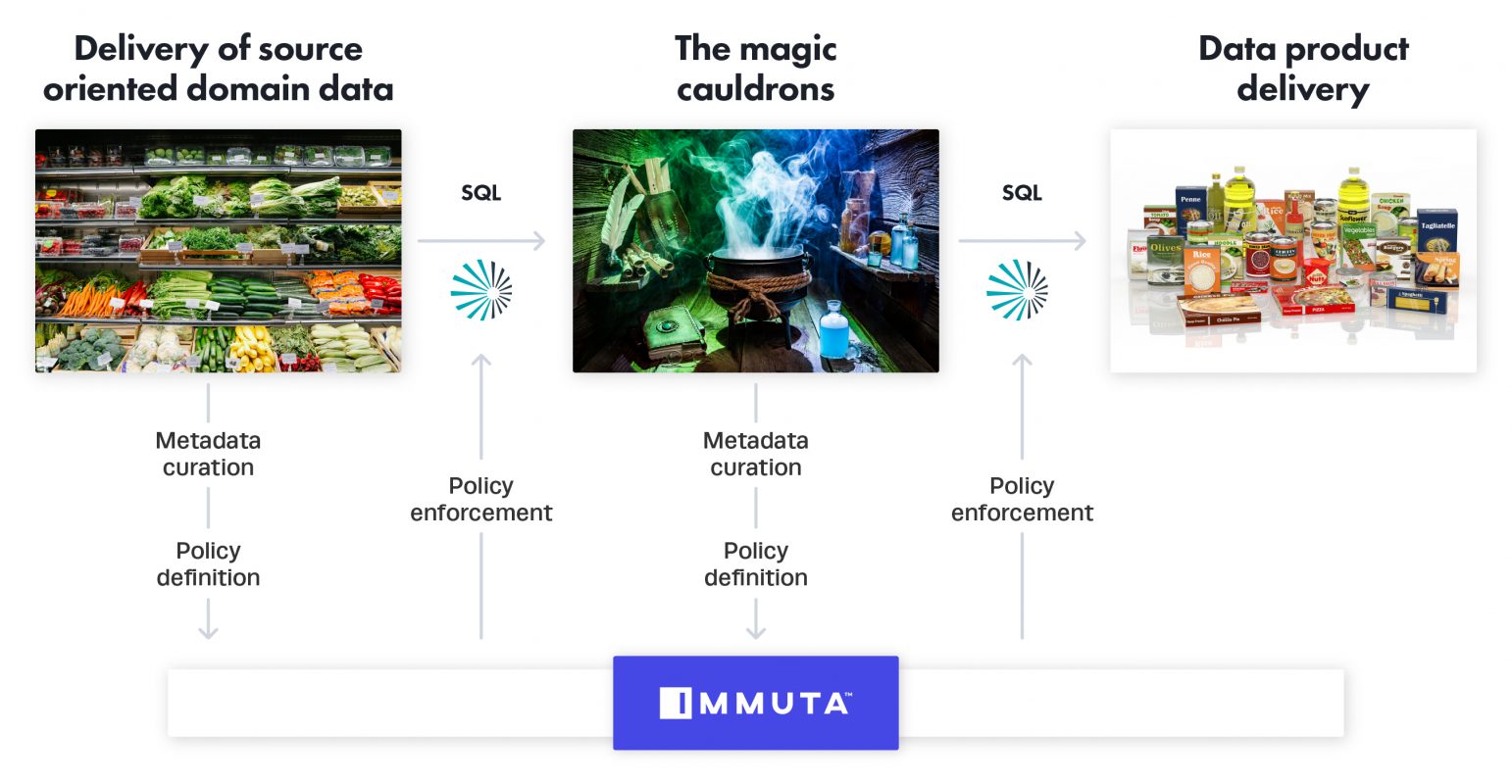
- Delivery of source oriented domain data: I like to think of this as your raw materials: carrots, potatoes, broccoli, cheese. It’s the critical foundational data components to your business that live in an operational system you don’t touch; it simply “feeds the data mesh beast.”
- The magic cauldrons: This is where the magic happens, the domain-specific innovation. Dehghani calls it “Consumer oriented and shared domain data,” which is the output — but a lot of work needs to occur to get there. Data products need to be designed and executed with whatever tools the domain deems necessary. I could build split pea soup from the raw materials from #1, where some other domain could build cheddar broccoli soup. The point here is that the magic cauldrons can boil up whatever they want, using whatever is available to them from a tools perspective, such as Snowflake, Databricks, Redshift, dbt, etc. You want to foster that innovation. Think of it as little “data startups” in your own organization.
- Data product delivery: This is the marketing and sales of your data products to downstream consumers in your organization. How do they find your data products? How do they “buy” them? How do they know what they are buying? How do you ensure they only get what they should get? etc.

Frameworks
Let’s focus on the arrows in that picture rather than the actual components described in the previous section. To make the data mesh work, the arrows are the most important part. Think about it — if you allow domain-specific innovation in the cauldrons, the only thing stopping you from succeeding is breakdowns in the arrows, right? If data product owners can’t get the data, you fail, and if they can’t deliver their data products, you fail.
You need standardized frameworks for those arrows – this is how you can ensure success of the data mesh architecture.
On the data delivery side, Dehghani argues that the “source oriented data be provided in easily consumable historical snapshots of the source domain datasets, aggregated over a time interval that closely reflects the interval of change for their domain.”
Similarly, for Data Product delivery, Dehghani argues domain teams “provide these capabilities as APIs to the rest of the developers in the organization, as building blocks of creating higher order value and functionality. The teams strive for creating the best developer experience for their domain APIs; including discoverable and understandable API documentation, API test sandboxes, and closely tracked quality and adoption KPIs.”
SQL As Your Framework
This is where I disagree with Dehghani. You should not use APIs for the delivery of data for analytics on either side of the magic cauldrons. Why? There’s already a universal API for delivering data called SQL — I have a feeling you’ve all heard of it.
There are three primary problems with APIs to deliver data products. I’ve personally seen these failures first hand multiple times in the US Intelligence Community where an “API-all-the-data” approach was used:
Problem 1: You need to deliver a data product
The argument can be made that the domain knowledge should be baked into the APIs. I’ll make the argument that what makes the Data Products special should be baked into the data itself. If you abstract that into the APIs, you are no longer delivering data products, you are delivering API products, which leads to our next problem…
Problem 2: Cross-domain analysis
Dehghani expresses “One of the main concerns in a distributed domain data architecture, is the ability to correlate data across domains and stitch them together in wonderful, insightful ways; join, filter, aggregate, etc.” This is quite literally what SQL was built to do with data, and it’s how all downstream tools expect to speak to your data. This is also why you need to bake innovation into your data, not your APIs. But the argument could be made that this assumes a single data warehouse, and because of that, we are stifling the magic cauldrons; we’ll come back to this.
Problem 3: Governance
Most organizations that integrate an API into their data mesh do it purely for governance. Where else would you provide the granular data access controls? But what if you could protect at the data level without APIs or stifling the magic cauldrons at all? You can.
Caveat: You of course need APIs for application building, but in this instance, we are referring to solving your first biggest challenge: how do you deliver data products for downstream analytics.
SQL Is Your Data Mesh API
We presented two counter-arguments above that if you use SQL for delivery of data products, you may defeat the purpose of the data mesh concept by forcing the domain-specific cauldrons into a specific warehouse paradigm. You also lose all granular controls because there’s no longer an API that contains your governance business logic.
Consider an externalized query service, like Starburst, and a data access control tool, like Immuta as the framework to enable data mesh and avoid these counter-arguments.
Dehghani states, “A data product, once discovered, should have a unique address following a global convention that helps its users to programmatically access it.”
Starburst Enterprise, based on open source Trino (formerly PrestoSQL), provides a common query tool that is abstracted from the systems that store your data. This enables you to run analytics on data where it lives — no data movement or copies required.
What this means is that you can lay Starburst on top of your domain-specific data products and deliver them in a consistent way (SQL). In fact, with Starburst’s new release of Stargate, you can lay Starbursts on top of Starbursts to provide further segmentation of domain ownership. This buys you a consistent framework for the delivery of data products, a way for consumers to access data products and, equally important, to join and aggregate them as needed.
Stealing more of Dehghani’s great content:
“A data product must be easily discoverable. A common implementation is to have a registry, a data catalogue, of all available data products with their meta information such as their owners, source of origin, lineage, sample datasets, etc.”
“Accessing product datasets securely is a must, whether the architecture is centralized or not. In the world of decentralized domain oriented data products, the access control is applied at a finer granularity, for each domain data product. Similarly to operational domains the access control policies can be defined centrally but applied at the time of access to each individual dataset product.”
Immuta provides a purpose-built data mesh catalog with fine-grained access controls. The beauty of Immuta is not only can you catalog and curate metadata about your data, but you can also apply fine-grained access controls at the data layer.
To understand this concept more deeply, policies that are built in Immuta act dynamically at query time (in SQL) to redact, anonymize, or restrict data. Immuta also empowers decentralized domain owners to control and manage their own metadata in the catalog; to not only curate it, but build policies against it using their domain knowledge. This is in contrast to other data governance tools, such as Apache Ranger, that assume a single set of administrators intimately familiar with the project who control all policy. This domain-level control enabled by Immuta is required for a data mesh architecture.
Let’s look at our diagram again, with Starburst and Immuta as your sharing framework and SQL as your API. In both cases, Starburst and Immuta, the SQL, catalog, and policies are abstracted from the actual warehouses/compute. That abstraction is exactly what you need to create a framework to make the data mesh vision work.
Conclusion
It’s easy to focus on the components of the data mesh but forget about the “arrows” between them. Without those arrows you will fail. We recommend a standard framework and language (SQL) to share your data products and serve as the core of your data mesh.
To see everything you can do with Immuta and Starburst together, request a demo today.



