The tension between quickly provisioning data access and maintaining control over it has been growing for at least a decade, but thanks to decentralized architectures, diverse cloud ecosystems, and — most critically — the widespread adoption of AI, it’s now reached a tipping point.
Since our inception, Immuta has addressed the need for consistent, accurate, and scalable data provisioning and governance in evolving data ecosystems by:
- Abstracting and federating policy authoring.
- Translating and provisioning those policies consistently across data platforms, lakes, and warehouses, no matter their primitives.
- Decoupling policies from role management in order to compress policies, and simplify policy authoring and comprehension.
Still, preparing and authoring those policies requires a certain level of technical acumen. And in the world of AI ubiquity and federated governance, most organizations want (and need) to delegate data policy ownership and authoring to non-technical data governance teams. We created Immuta Copilot, the first of our Immuta AI capabilities, to bridge that gap and enable policy authoring at the speed and scale of AI.
Immuta Copilot at-a-glance
Immuta Copilot simplifies the responsibilities of non-technical data governance teams across lines of business, allowing them to own and manage data access policies consistently, correctly, and most importantly, with confidence. And as AI gives way to more human and agentic users, Immuta Copilot allows governance teams — tasked with reviewing and approving data access requests for the entire business — to keep up with an influx of requests, without delays, gaps, or compromise.
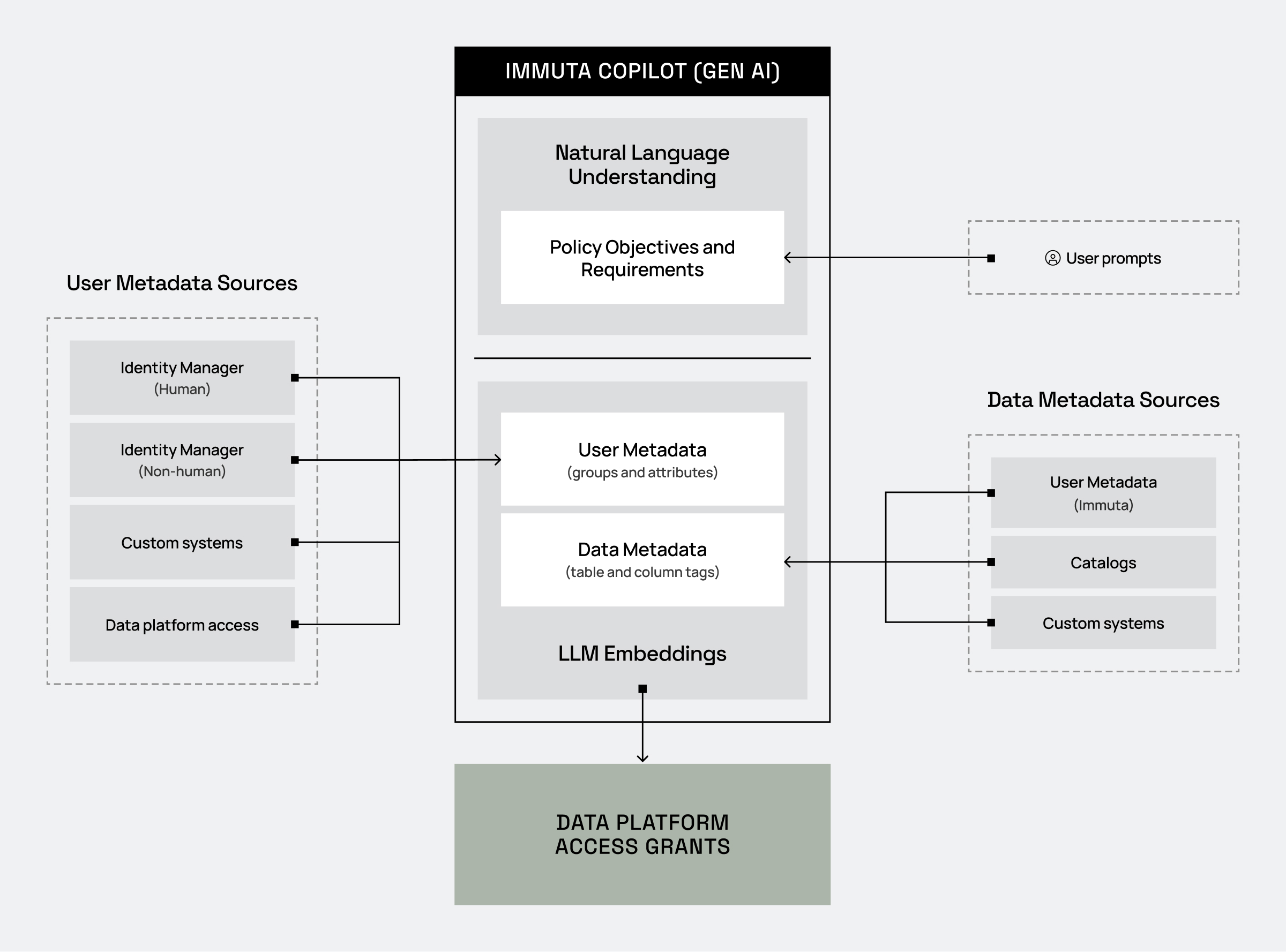
How does Immuta Copilot work?
Every data platform, lake, and warehouses manages data access controls slightly differently, but by and large, access is managed via “database roles.” While this approach seems effective on the surface, it ultimately leads to more access permutations than is manageable — leading to role explosion. You can read more about that here.
Immuta eliminates role explosion through policy compression and abstraction. Instead of defining a role, who belongs to that role, and the associated level of access, you instead:
- Define users with metadata (facts about the users).
- Define data with tags (facts about the data).
- Define policies for what kinds of users (using the user metadata) should have access to what kinds of data (using the data metadata/tags).
This results in far fewer human readable and comprehensible policies.
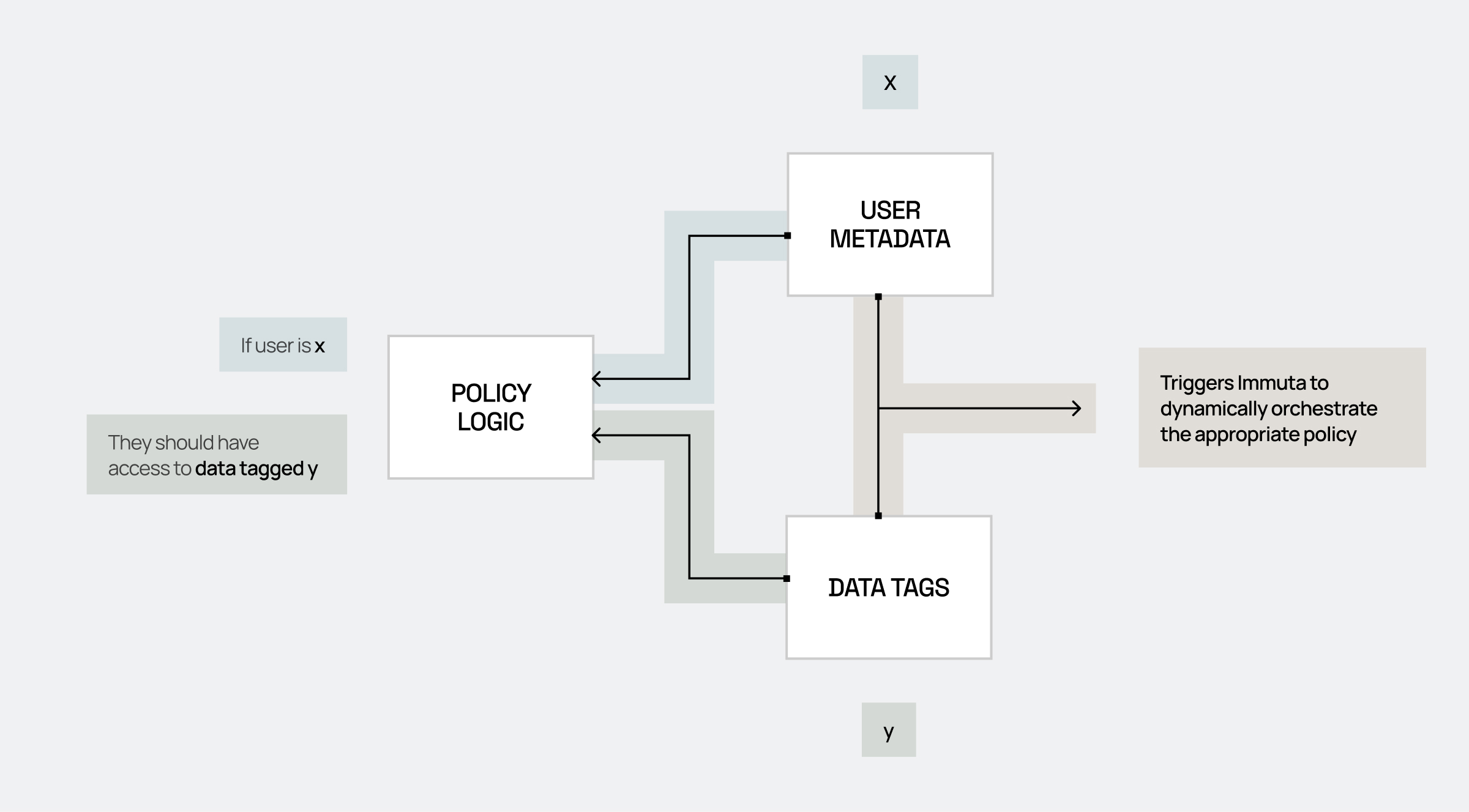
Because of this, policies can be defined in a sentence-like format:
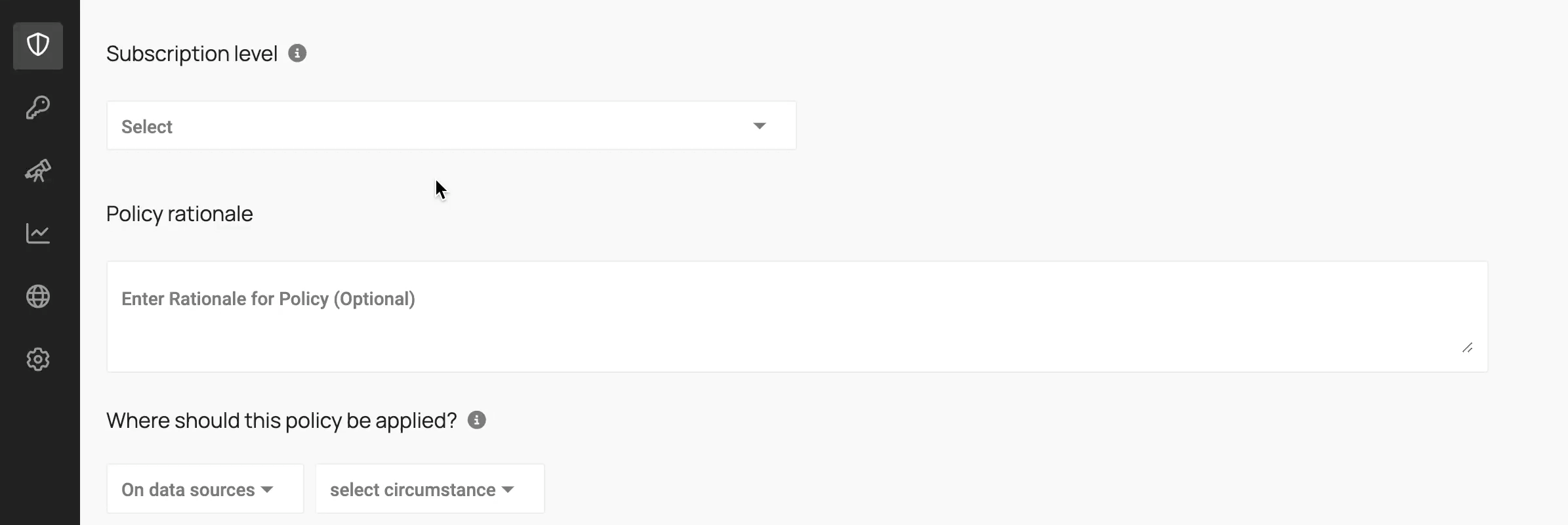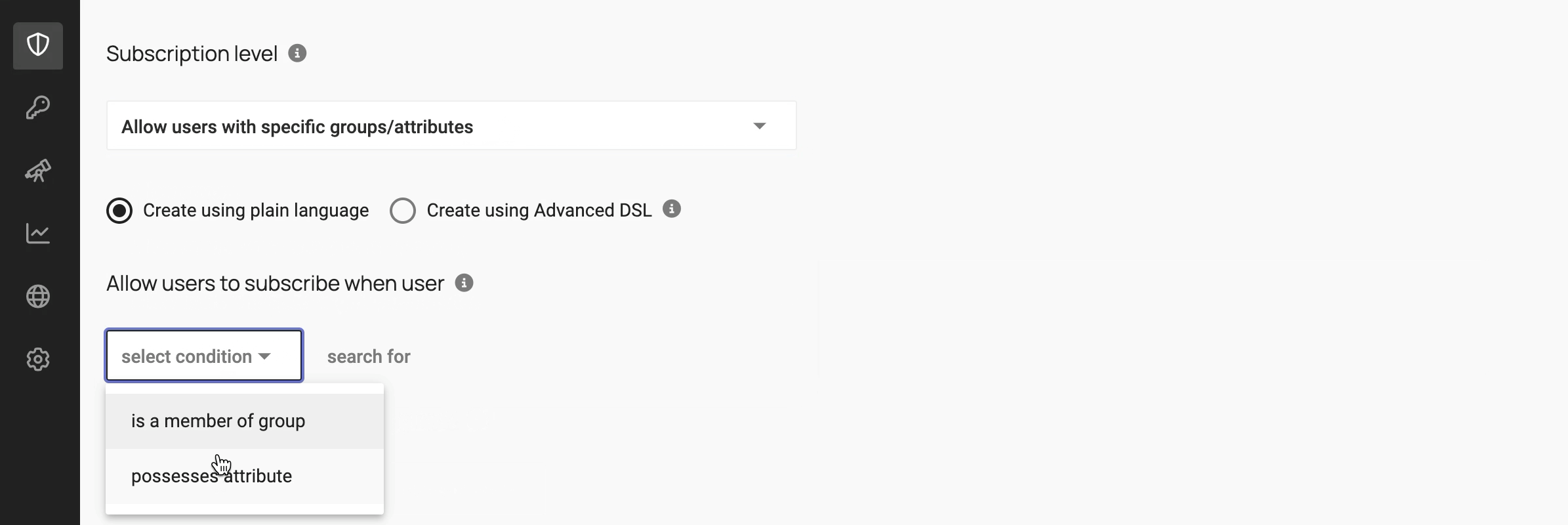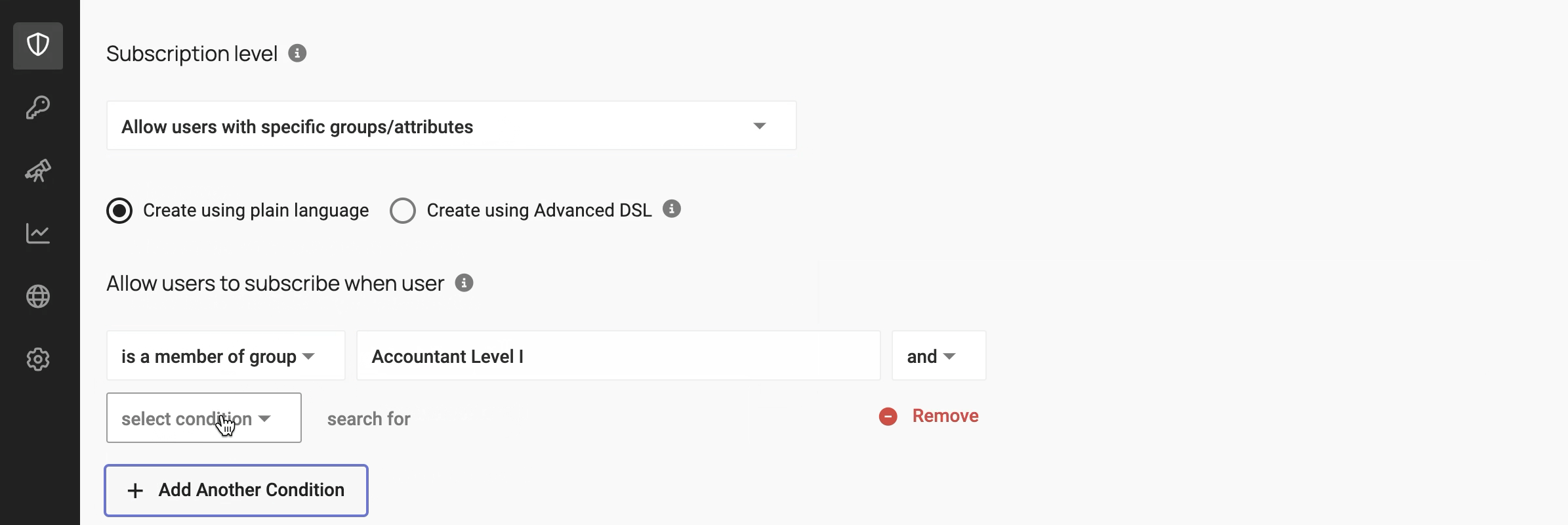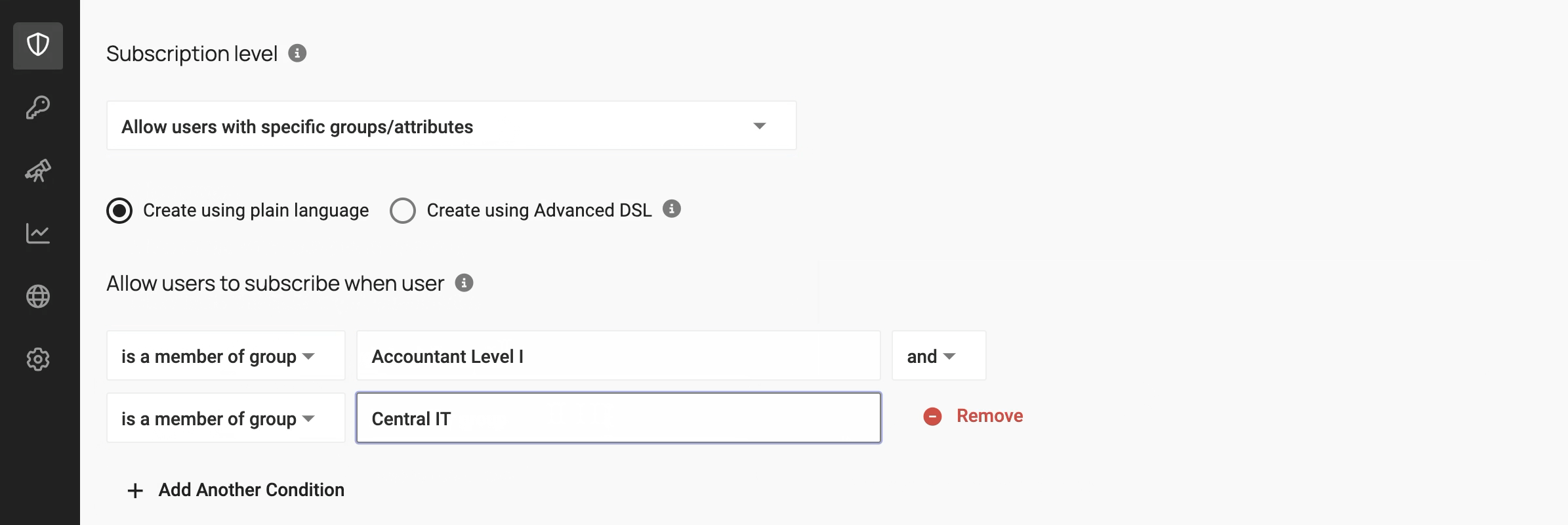
This approach to policy compression and abstraction is the basis for Immuta Copilot. With this capability, you can simply describe the policy that you want to apply by writing a free-form text prompt like this:
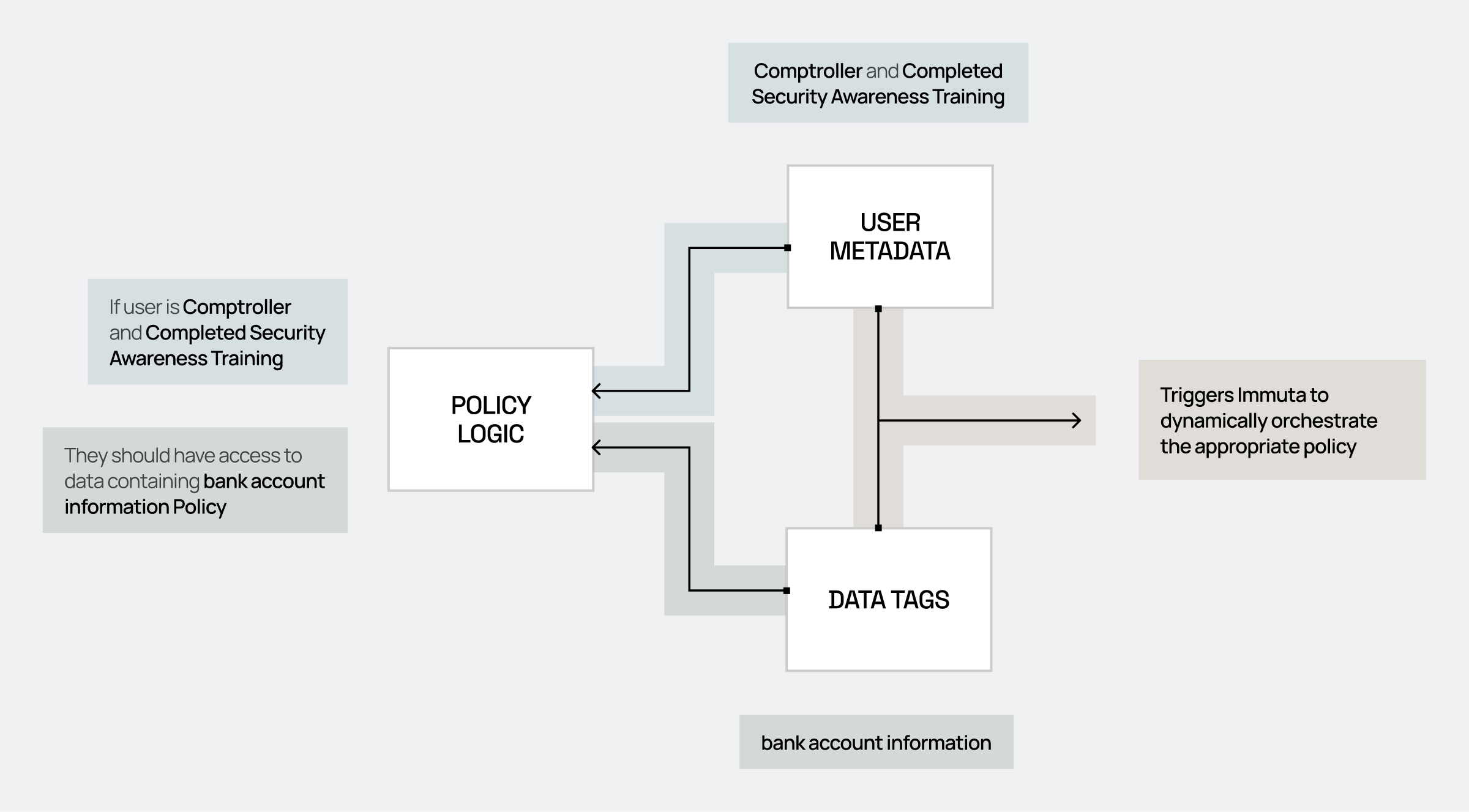
Comptrollers can read data containing bank account information after completing security awareness training.
Under the covers, Immuta Copilot will break this sentence down into the components required to translate it into an access policy:
Subjects: Comptrollers
Objects: Data containing bank account information
Conditions: Completed Security Awareness training
As you can see, the sentence components align to the access policy diagram:
User Metadata: Comptrollers, Security Awareness Training
Data Metadata/Tags: Data containing bank account information
Policy: If those two conditions match, provide access
From these inputs, Immuta Copilot will automatically generate the following policy:
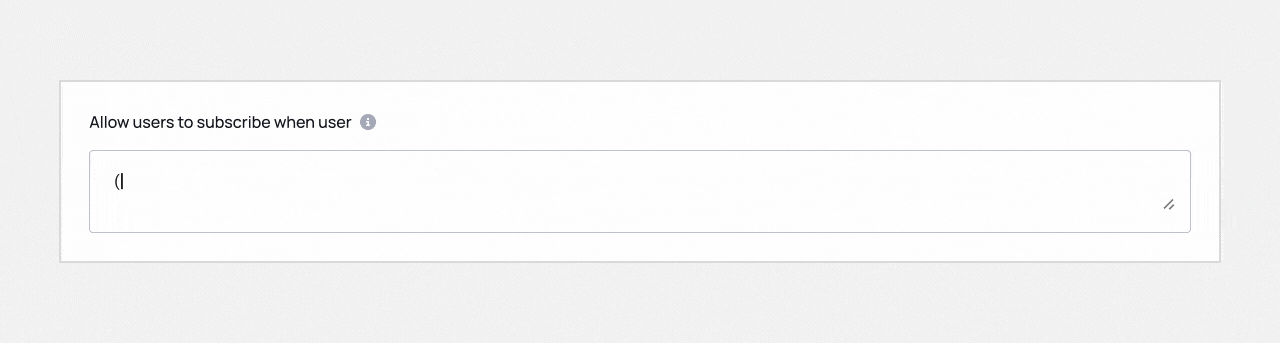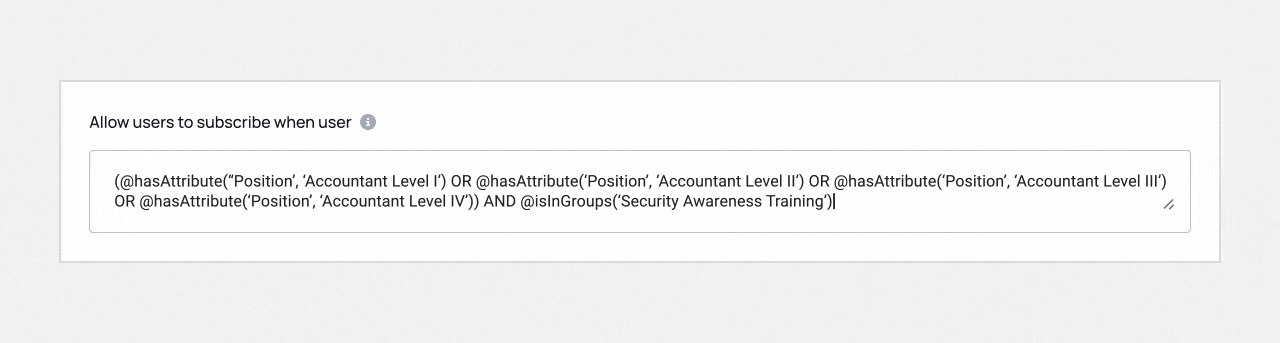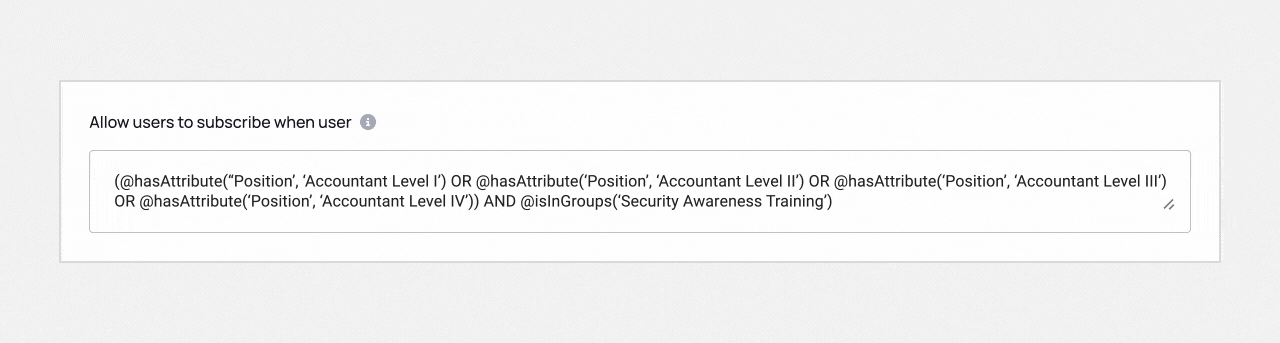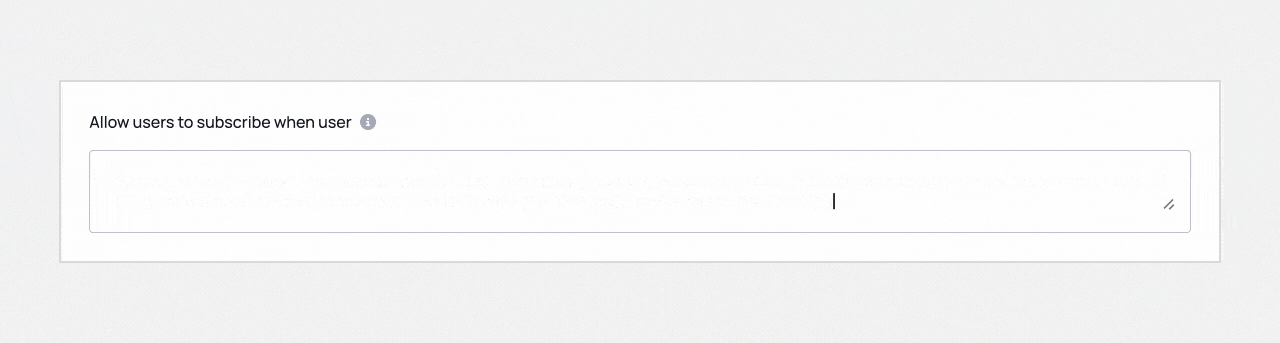
You might be wondering why you don’t see Comptroller anywhere above, and instead see different accountant levels listed. That’s the beauty of Immuta Copilot — it can interpret your original sentence and select the appropriate user metadata based on the intent of the sentence.
For non-technical users, this is a massive help in describing policy intent without having to understand the nuts and bolts of the entire Immuta system. They also don’t need to worry that they are missing a set of users, which instills confidence and helps them validate correctness more quickly.
Similarly, there is no mention of bank account information. Instead, the data metadata targets tags (pre-existing or to-be-determined) on the data that align to bank account information. Here again, Immuta Copilot automatically makes that connection based on the intent of the sentence. Similar to the Comptroller example, this ensures data governance teams have covered all data containing bank account information with this policy — quickly — without having to know about every data tag or worry about inconsistency across platforms.
Using metadata for AI-driven policy authoring
Immuta Copilot works well because of how Immuta policies are defined in the first place: user metadata and data metadata/tags. This is how policies are described in the real world, and therefore it works when written in a sentence.
You may hear vendors that say they do “ABAC” or “tag-based policies,” but since it only focuses on the data metadata/tags, that is only 50% of the solution. Without the user metadata, you would need a role (or group) that represents all the accountants that also have completed security awareness training — for instance, comptrollers_w_security_awareness_training. With Immuta Copilot, however, the metadata is neatly referenceable by the language model and composable with boolean logic.
This means that Immuta Copilot-generated policies are not only highly scalable, but can also be implemented quickly. In turn, data consumers get faster access to the datasets they need.
Immuta Copilot is currently in Private Preview.
What's Next?
Policy Recommendations
Next, we will build on Immuta Copilot with Policy Recommendations. This is where the data governance teams managing approvals and drowning under the weight of “everyone is a data consumer” start to feel relief. Here’s how it works:
- Immuta AI will monitor and find trends in approvals and denials over time by analyzing commonalities in approved users’ queries, attributes, and groups, as well as metadata on the tables they are accessing.
- Using that information, Immuta AI will anticipate future “like” users that may need access, and provide recommendations to data governance teams.
- Once a bulk-approval or policy recommendation is green-lighted by the governance team, it can be enforced at scale.
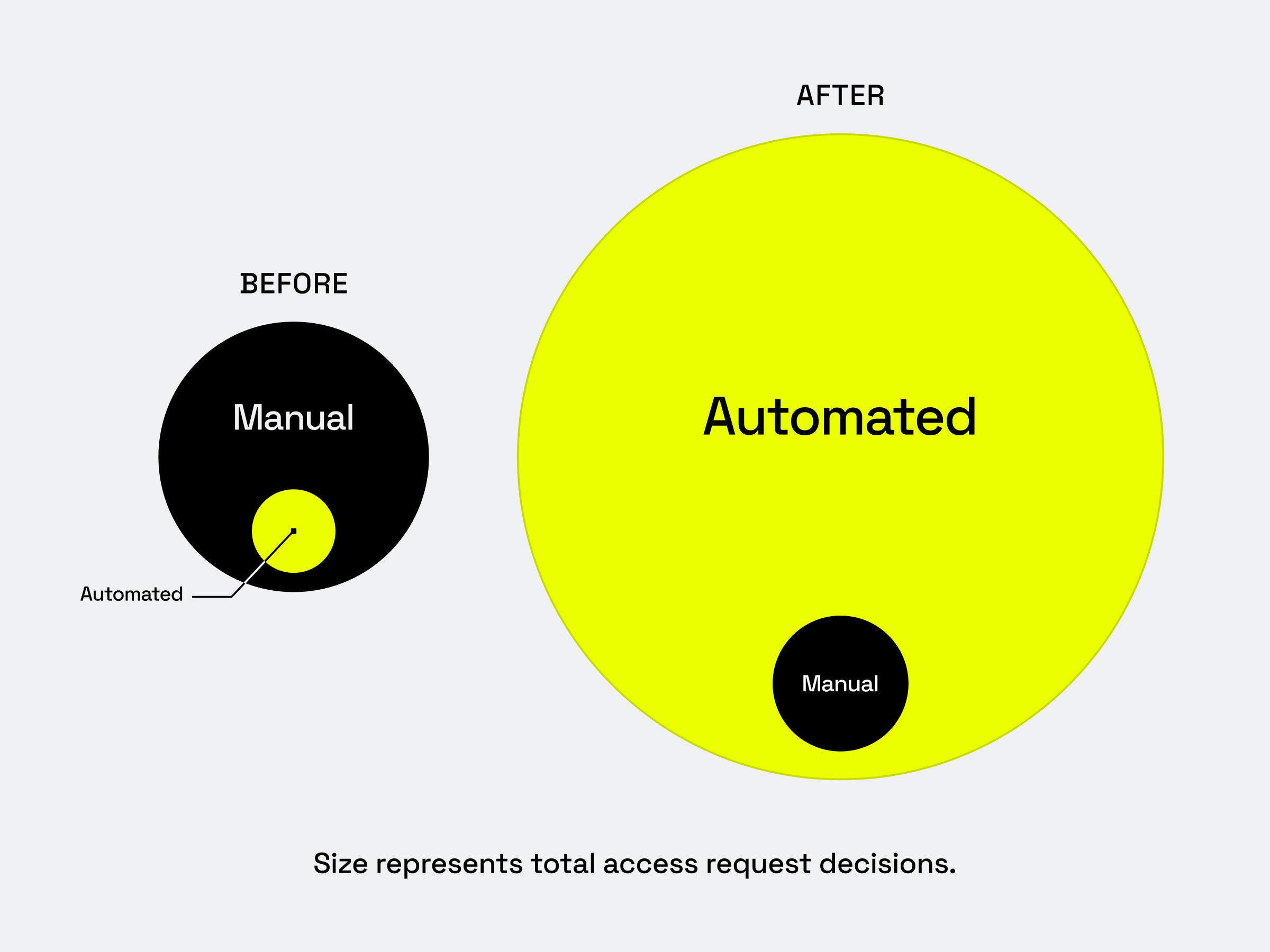
With policy recommendations, Immuta AI can pre-compute what would previously have been one-at-a-time manual approvals and quickly transform them into scalable policies in the Immuta Data Marketplace solution. As trends become clear over time, the amount of approvals should shift from 80% manual / 20% automated, to 20% manual / 80% automated, while still supporting decentralization.
In this architecture, you can see that the agentic context analysis builds on top of Immuta Copilot capabilities.
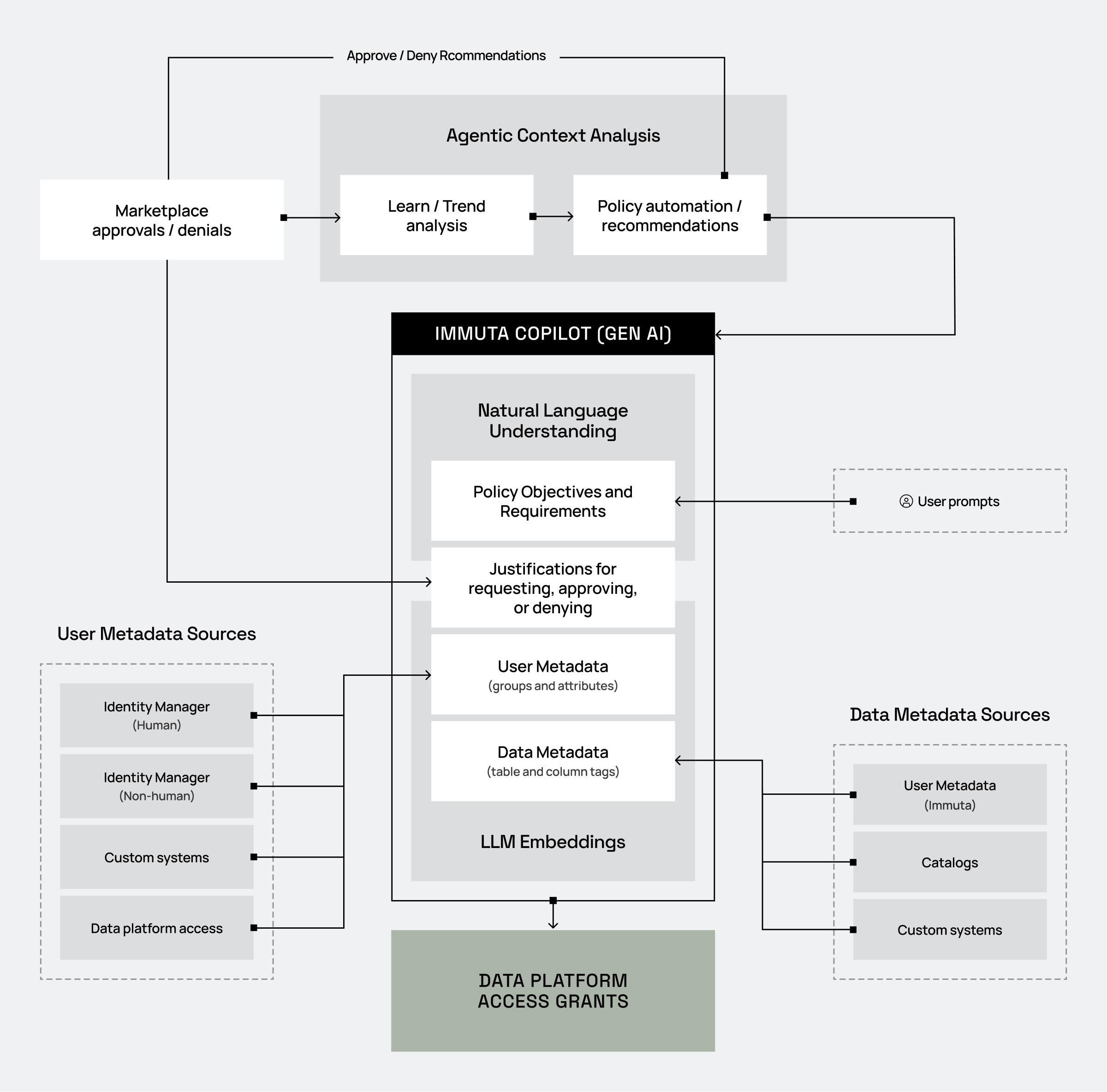
We expect to deliver policy recommendations shortly after Immuta Copilot.
Access Recertifications
Since data governance teams are also tasked with recertifying that access is still required after a given time period* — which is an extremely manual, burdensome, unscalable process — Immuta AI will also simplify access recertifications.
With this capability, the same agents that recommend policy can also make recommendations on whether access should be retained over time. This is done using inputs such as how often the user is querying that data and/or whether the user’s queries align with the stated usage purpose. This will scale access recertifications and make them more consistent.
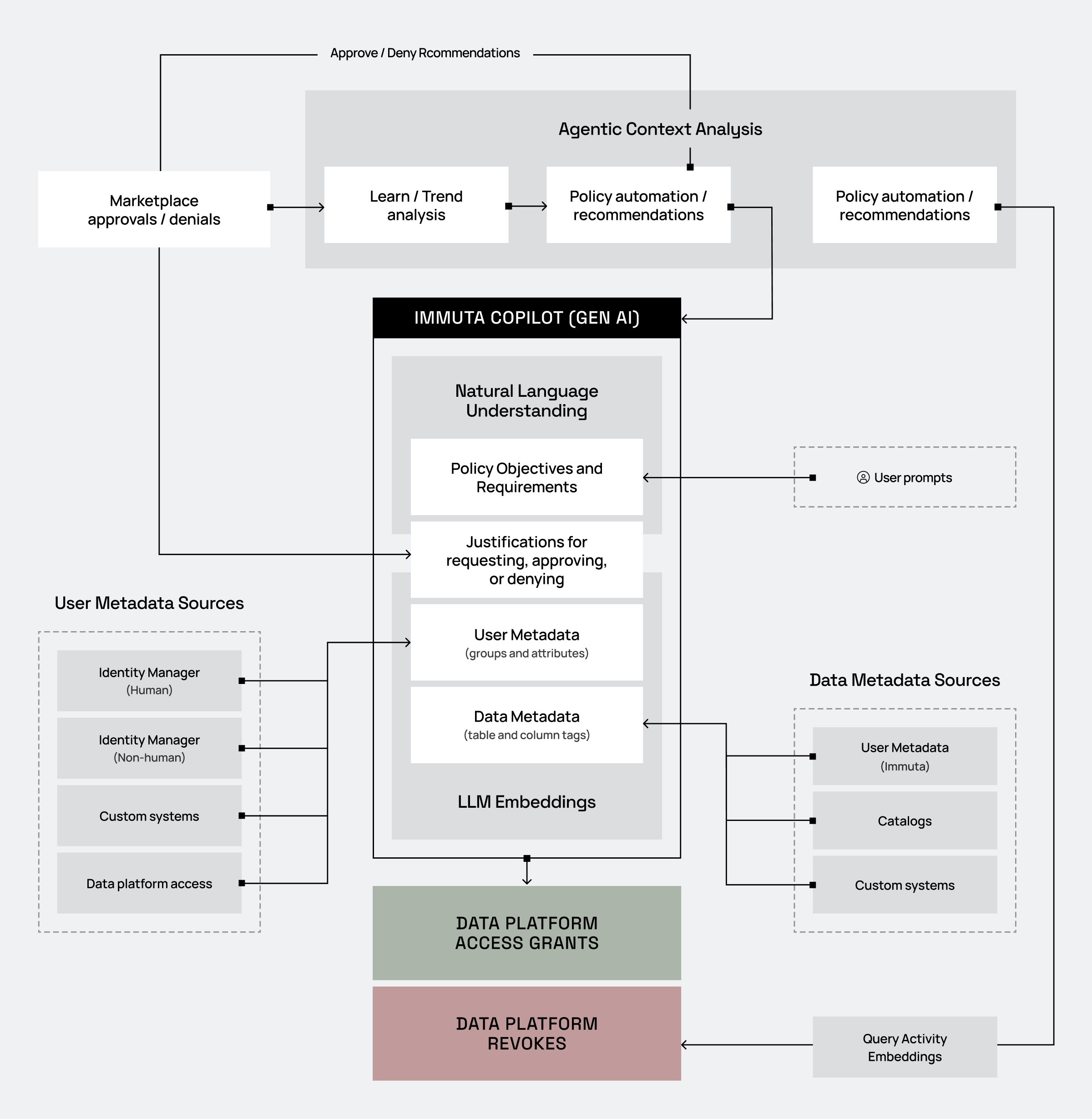
*Immuta’s marketplace also supports temporary access approvals. For example, it is possible to state that you will give someone access, but only for a month. When that month has been reached, Immuta will automatically revoke access. This can also remove the burden of access recertifications.
Conclusion
Immuta’s dynamic access controls and governance model set the foundation for working with LLMs, and Immuta AI will build a powerful layer onto that foundation. With robust metadata, native integrations with leading cloud platforms, and connectivity to our Data Access Governance and Data Marketplace apps, Immuta AI will enhance speed, accuracy, reliability, and scale — all while easing the burden on data governance teams and empowering them to keep up with the pace of AI-driven data demands.
Get started now.
To learn more about Immuta AI, get in touch with our team.



