
Organizations expanding their cloud data ecosystems (multi- and cross-cloud services for building data products) are faced with a number of options on where to enforce fine-grained access control policies on sensitive data, including security and privacy controls. As modern cloud architectures decouple compute and storage layers, the policy tier that governs and enforces data access becomes heterogeneous as new use cases are onboarded. Adding best-of-breed cloud data capabilities brings increasingly complex authorization logic that can get distributed across different layers, from object store compute engines to analytical tools. For centralized data teams managing access requests that protect data and provide transparency in order to answer very basic questions, such as who can use what data, when and for what purpose, this introduces significant risk.
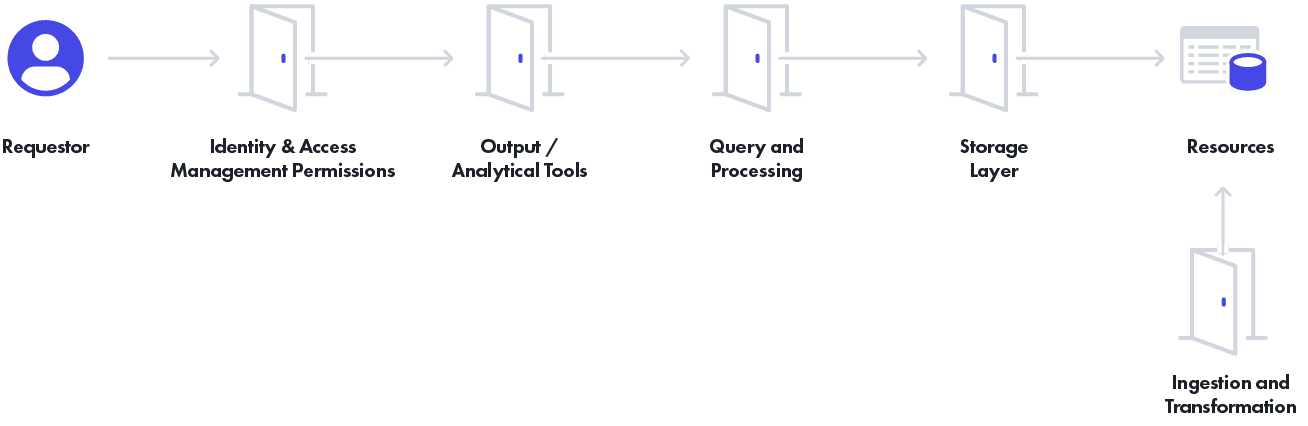
Let’s contrast effective policy enforcement across the different “doors” into your sensitive resources, which require fine-grained access control policies, by looking at the dimensions of:
- “Safety” – what is the risk for unauthorized access, or effectively, a data leak?
- “Utility” – is the accessible data usable for creating business value?
- “Scalability” – can this approach support increasing numbers of users and policies/rules?
Ranking each layer will be based on ecosystems that have at least one cloud-native data platform (i.e. not a hosted RDBMS such as MySQL or Postgres) with basic rules to segment data for one or more tenants (such as business line, geography, etc) and a requirement to mask sensitive fields for a subset of users.
If any of these doors is left open by design (i.e. maybe one group requested direct access to the object store despite the risk) or by accident (i.e. upon deployment of policy code changes), it can result in a data leak, which translates to a lot of bad scenarios.
To put the layers in context of a modern data architecture (created by a16z), this roughly translates into the stages from left to right, starting with Ingestion and Transformation:
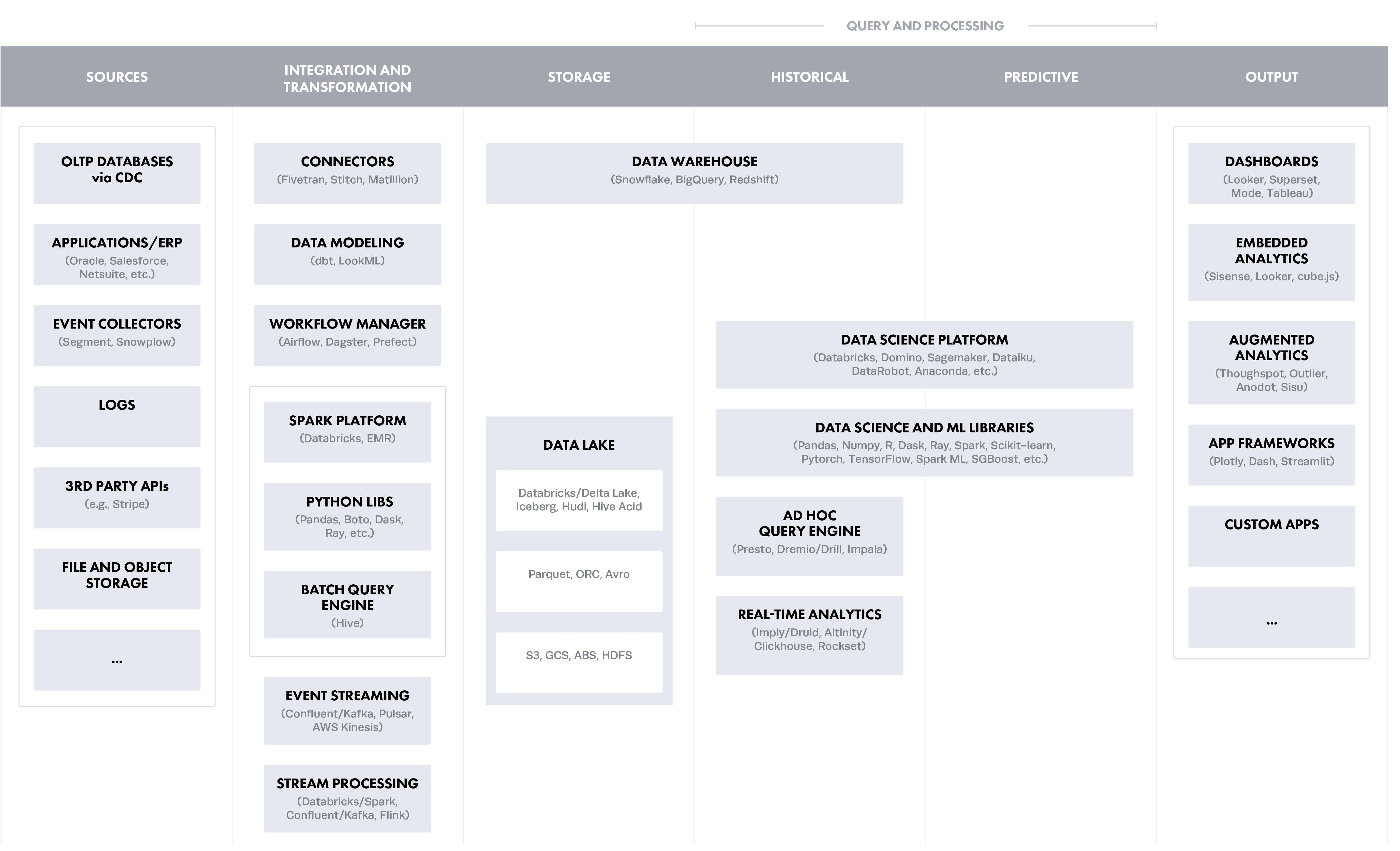
Option 1: Ingestion and Transformation Layer
The easiest way to protect sensitive data is to not make it available in the first place. This can be done by static masking of sensitive data on ingest, but that comes with a trade-off on utility. If the data is unusable, this approach can defeat the purpose of creating business value from it.

A common architecture pattern in on-premises architectures using ETL tools was masking data prior to load into a database, such that data was protected at rest and for subsequent use. There are tools that include some unmasking capabilities and operations but have a severe impact on data utility, essentially, once masked or encrypted on-ingest, you have removed nearly all utility from that column. Gartner’s Market Guide for Data Masking (December 2020) discusses this approach, described as static data masking (SDM), which reached its plateau of productivity back in 2017.
| Safety |
High |
Data is protected at rest. |
| Utility |
Low |
Raw data is generally inaccessible to users. |
| Scalability |
Low |
Data access policies require duplicating data for different users. |
Option 2: Storage Layer (Object Store Controls)
This would be the best place to protect data from a data platform architecture in an ideal world. However, object stores were not built for managing fine-grained access control to a particular subset of an object. For example, Amazon S3 provides bucket policies and user policies for granting permission to coarse-grained S3 resources, and similar concepts apply for ADLS or GCS. However, these cannot actively filter or mask rows and columns in structured data without compute resources. While creating access control policies at the storage layer may sound logical, it is still a raw storage layer and organizations managing sensitive data should remove direct access to it. Effective policy enforcement will require compute resources, such as those in the next option.
Ali Ghodsi, CEO of Databricks, recently shared during his keynote at Data + AI Summit 2021 that reading directly from data lakes can result in a data swamp due to governance challenges.
| Safety |
Low |
Coarse-grained access introduces risk for data leaks. |
| Utility |
Low |
Access to objects is “all or nothing,” meaning data made available has utility for authorized users; but this increases the number of non-authorized users with zero utility. |
| Scalability |
Low |
Coarse-grained access does not scale with more policies. |
If the data is not sensitive, this is a good option and credentials can be passed through from cloud data platforms that process the data.
Option 3: Query and Processing Layer (Cloud Data Platforms)
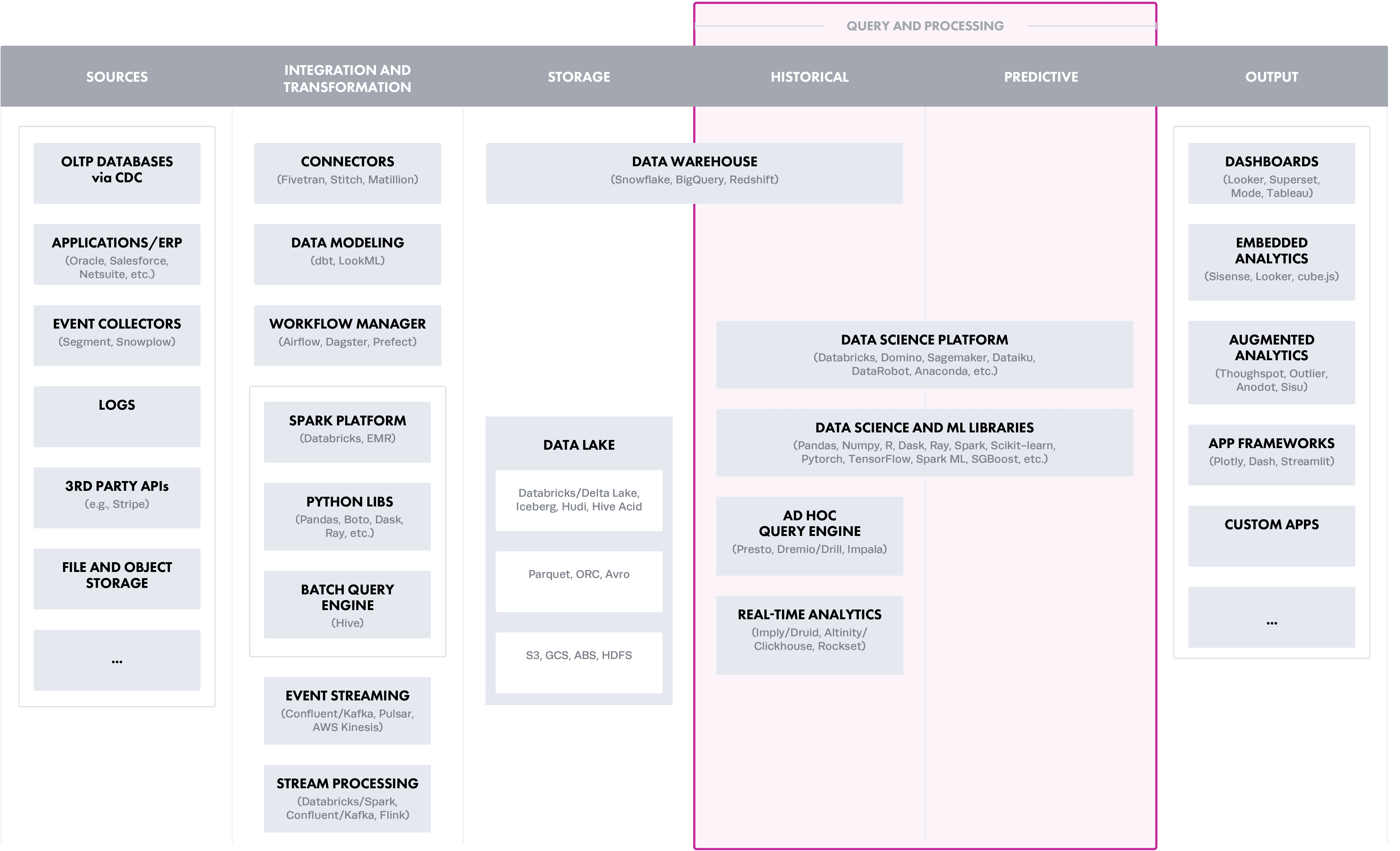
Cloud data platforms, such as Databricks, Snowflake, or Athena, represent the layer where data processing, or compute resources, is required to actively filter or mask data when accessed for policy enforcement. This may work with a single cloud data platform and simple rules for data access. However, as the number of platforms and/or rules increases, native access controls are generally limited and unable to scale in more complex data environments. For example, implementing a policy limiting users’ data access to their individual business units is very different among Snowflake vs Redshift vs Databricks. This results in an architecture that is challenging to secure and that has an increasing surface area of risk with each added platform or rule.
| Safety |
Varies from Low to Medium |
Native controls may work well for basic policies, but each platform has a wide range of support that is not consistent. |
| Utility |
Varies from Low to Medium |
Native controls may work well for basic policies, but each platform has a wide range of support that is not consistent. |
| Scalability |
Low |
Implementing controls for each platform does not scale and each platform handles controls differently, causing great confusion when a policy needs to be changed. |
Option 4: Output Layer (Analytical Tool Controls)
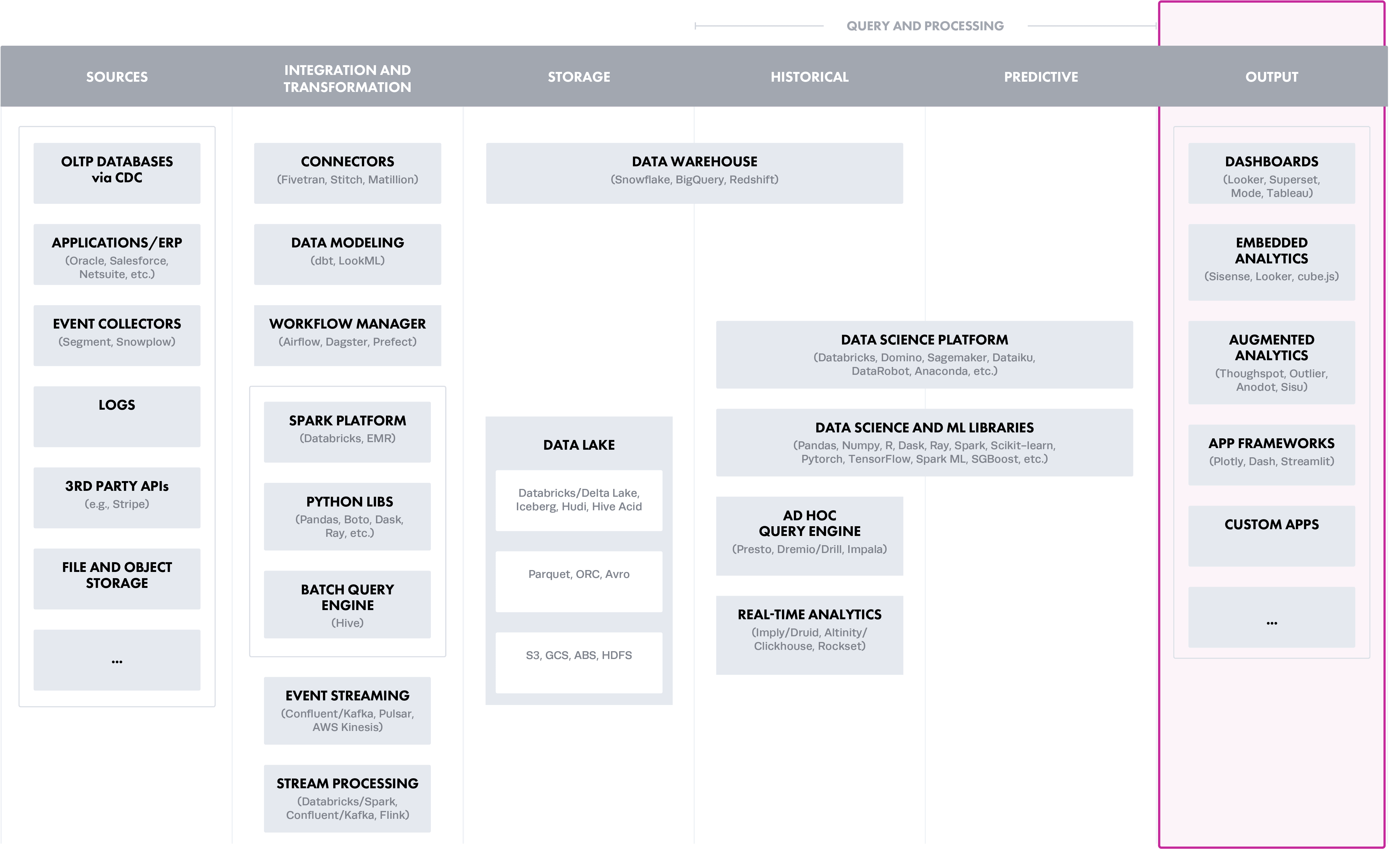
Analytical tools are increasingly delivering capabilities to store (usually as extracts) and process data, adding to the proliferation of policy enforcement points. Big clouds have tools such as Power BI on Azure or Amazon Quicksight, as well as popular cloud agnostic tools, such as Tableau or Looker, all of which use different approaches. For example, in Tableau, you can implement RLS by creating a user filter and mapping users to values manually; or by creating a dynamic filter with calculated fields to automate the steps.
While doing policy enforcement in this layer alone introduces risk, this approach can provide flexibility for analytics team consuming data. This assumes the supply-side data team has proper controls, meaning the doors leading up to this point are properly secured.
| Safety |
Low |
Data will be leaked when accessed outside of the tool with policy enforcement. This can create a huge problem with “shadow IT” at the output layer, which happens quite frequently. |
| Utility |
Varies from Low to Medium |
End users can use the data they are authorized to see, but analytical tools lack advanced techniques to mask or anonymize data while preserving utility. As discussed in the previous section, there is inconsistency in what kinds of rules can be applied. |
| Scalability |
Low |
This will not scale when adding new policies or new interfaces to access data. |
Option 5: Decoupled Policy Enforced on the Query and Processing Layer

The commonality across options 1-4 is that supporting scalability, additional users, and rules/policies is low, in part because the logic is embedded in each layer. Similar to how the separation of compute and storage enables scalable cloud data processing, it’s becoming necessary to separate the policy layer from the cloud data ecosystem to scale user adoption in complex data environments.
Of the policy layers, it’s also clear the query and processing layer is closest to storage, while its data processing capabilities make it ideal to set up a decoupled policy enforcement strategy. This leads us to option 5. Decoupled policy layers are driven by metadata, and either discover and classify it internally or integrate with catalog sources, such as Alation or Amazon Glue, to enforce policies centrally.
| Safety |
High |
Decoupling policy enforcement at the query and processing layer provides the best option across the cloud data ecosystem because it centralizes policy definition and expectations through a consistent abstraction. This is the same reason you decouple your identity manager from your data tools. |
| Utility |
High |
Using a tool purpose-built for enforcing fine-grained controls will give you the most advanced policy techniques on the market, rather than a “feature” in an existing compute or output layer tool. |
| Scalability |
High |
Centralizing policy management provides the best option to scale. |
Summary
When looking at the different layers for policy enforcement in cloud data ecosystems with sensitive data, there are trade-offs across safety, utility, and scalability. The chart below tallies up the scores for the dimensions listed above based on the baseline assumptions introduced earlier. Higher cumulative numbers translate into safely unlocking the most sensitive data where values for each attribute are Low=1; Medium=2; and High=3.
This does not take into account combining options, but the general guidance is that the lowest score for any option you adopt with user access applies to the entire data ecosystem. This is why many organizations work to remove direct access to structured data in the storage layer.
| Ingestion and Transformation Layer |
Medium (5) |
| Storage Layer (Object Store Controls) |
Low (3) |
| Query and Processing Layer (Cloud Data Platforms) |
Varies from Low to Medium (3-5) |
| Output Layer (Analytical Tool Controls) |
Varies from low to Medium (3-4) |
| Decoupled Policy Enforced on the Query and Processing Layer |
High (9) |
| Multiple (Options 2-5) |
Select lowest score of the options with direct user access. For example, setting policies for user access to an object store (Low), combined with policies set for the query and processing layer (Low to Medium), will be Low. |
The decoupled policy enforced on the query and processing layer has the highest score. There are cloud-native services, such as AWS Lakeformation, that can decouple some policy enforcement for select AWS services, such as Athena, Redshift, and EMR. However, these services lack row level segmentation and a consistent way to define policy across those compute technologies, even though it is decoupled. Immuta is a cloud agnostic solution that works across query and processing layers in AWS, Azure, and GCP, with a full suite of fine-grained access controls required to meet the outlined scenario.




{kind=link}