The Ultimate Guide to Data Access Control in Snowflake
Content Bundle


“Over the past few years, data privacy has evolved from ‘nice to have’ to a business imperative and critical boardroom issue,” warns a Cisco benchmarking report.
Security and privacy are colliding in the cloud and creating challenges like we’ve never seen before. This is particularly true for organizations making the move from on-premises database warehouses to SaaS-based data platforms, like Snowflake, where users outside the organization — such as cloud and SaaS providers — need to be trusted at some level. To tackle this problem, you need to think about layers of trust and where you want that trust to live in conjunction with data utility tradeoffs.
Let’s explore these different levels of trust and what protections can be deployed to make them practical.
To set the stage, we’ll first focus on privacy. There are four main categories of data privacy:
Sensitive information can overlap with indirect identifiers (e.g., a health condition you have). This makes indirect identifiers interesting — they can straddle the line between both sensitive information and direct identifiers.
How can an indirect identifier be a direct identifier? Consider the Netflix Challenge privacy scandal. When Netflix released its data for the challenge, it contained no direct identifiers indicating who rated what movie. The data included the ratings themselves, along with other information to help build movie predictions. One may think this is simply categorized as “other data,” but by taking the ratings and comparing them to other movie rating sites, the attacker was able to identify the individual movie raters. This linkage attack ultimately led to the lawsuit. The ratings themselves — presumably the most important parts of movie prediction algorithms — are, in fact, also indirect identifiers that violated privacy!
To effectively deal with privacy, you have to not only manage direct identifiers — depending on your legal and ethical obligations, you also need to protect indirect identifiers and sensitive information from your own employees. This is key because often indirect identifiers and sensitive information are the actual data you want and/or need to analyze. As you can see from the Netflix Challenge, movie ratings can’t just be “turned off.” So, what are you supposed to do? We’ll come back to that.

Content Bundle
Security is a different but related beast. Specifically, security breaches concern direct identifiers. If someone breaks into your database account, for example, they can immediately read your data and see everyone’s credit card number. Imagine if that person was your own disgruntled database administrator (DBA). Essentially, all an attacker is trying to do is gain illegitimate access to your employees’ legitimate rights — especially administrator-level access. If someone has unfettered access to your data, they can see all your data, no matter the privacy category.
Let’s consider the following diagram and table, and imagine there are no controls at all:
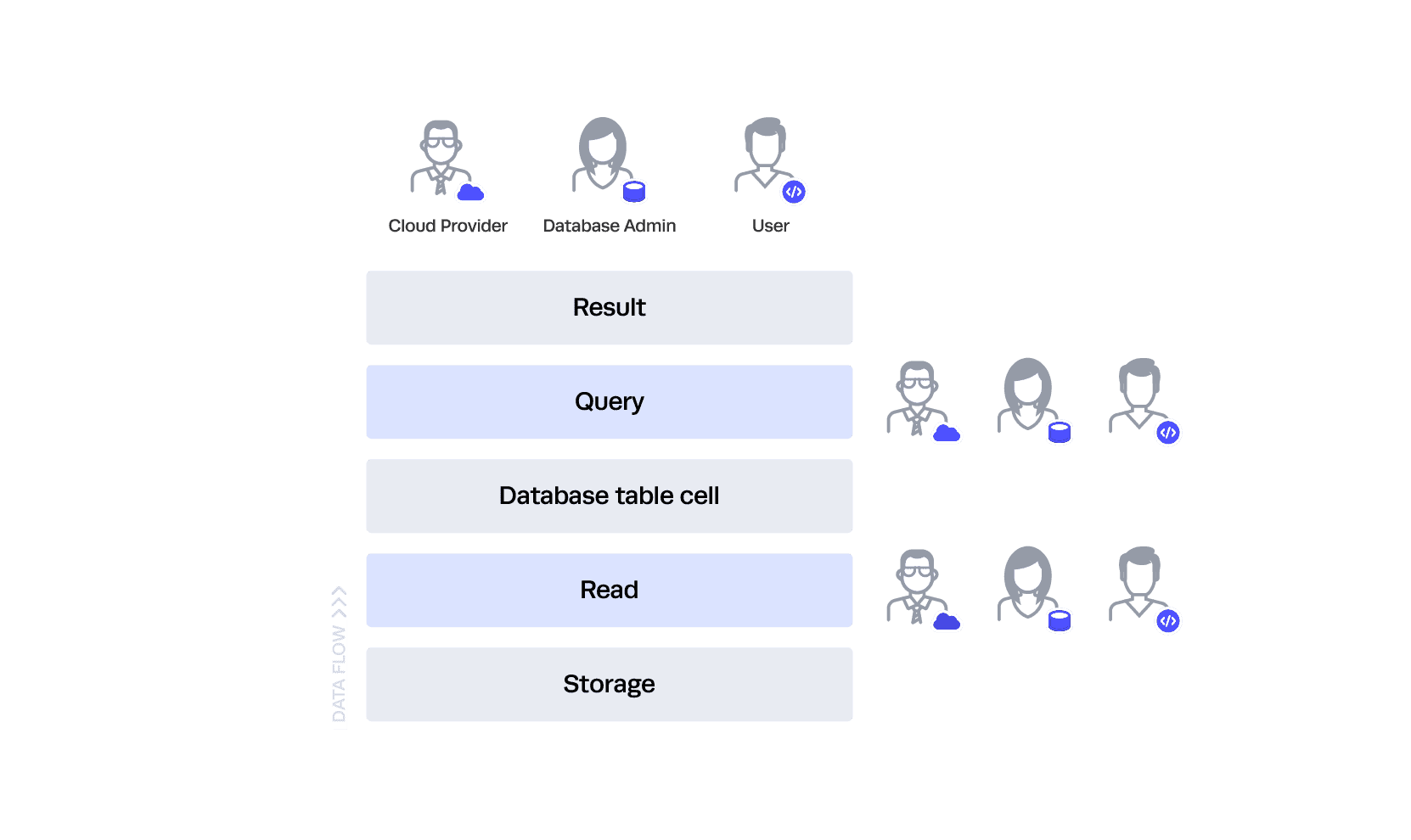
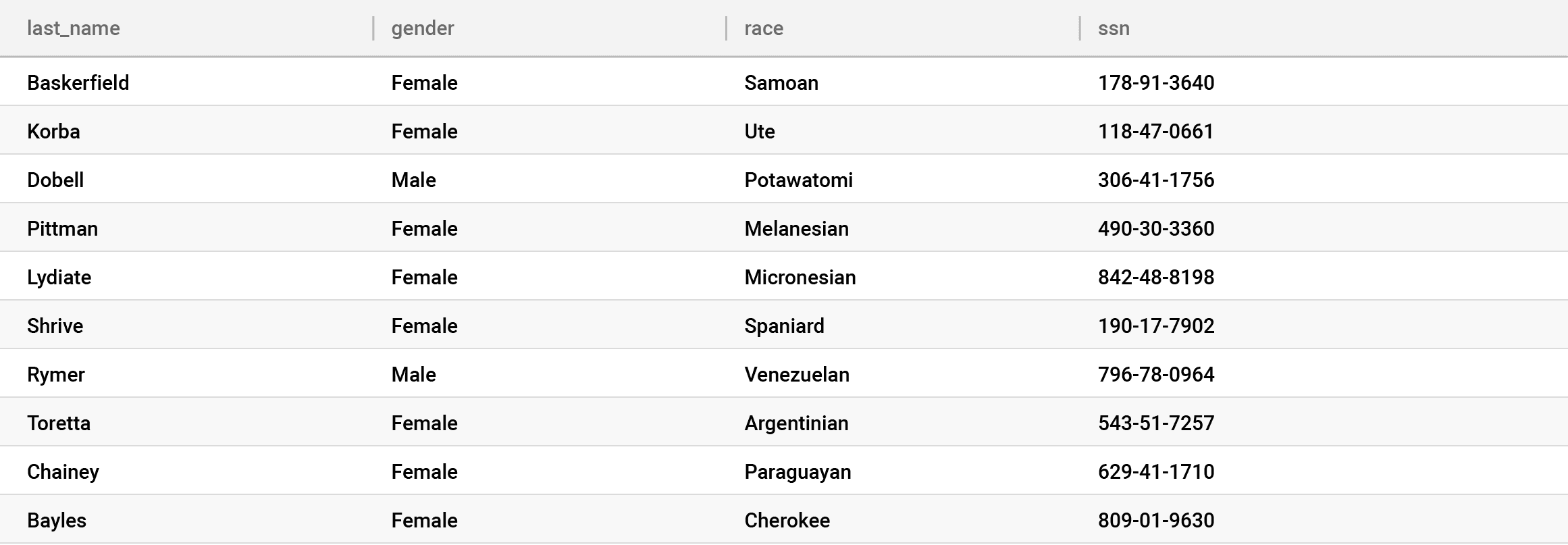
In this scenario, all three personas can run queries against any table. Additionally, they could bypass the database altogether and read directly from storage. Note that we are oversimplifying “read” from storage in this example. This does not mean “read” through a service, but rather literally reading the data directly from the hard drive.
This architecture should be undesirable for everyone. Let’s move to the next level.
You probably don’t want to trust your DBA or a user to read directly from storage — that’s the purpose of the database and the database controls (which we’ll get to in a bit). This is why both your cloud service provider and Snowflake use encryption at rest.
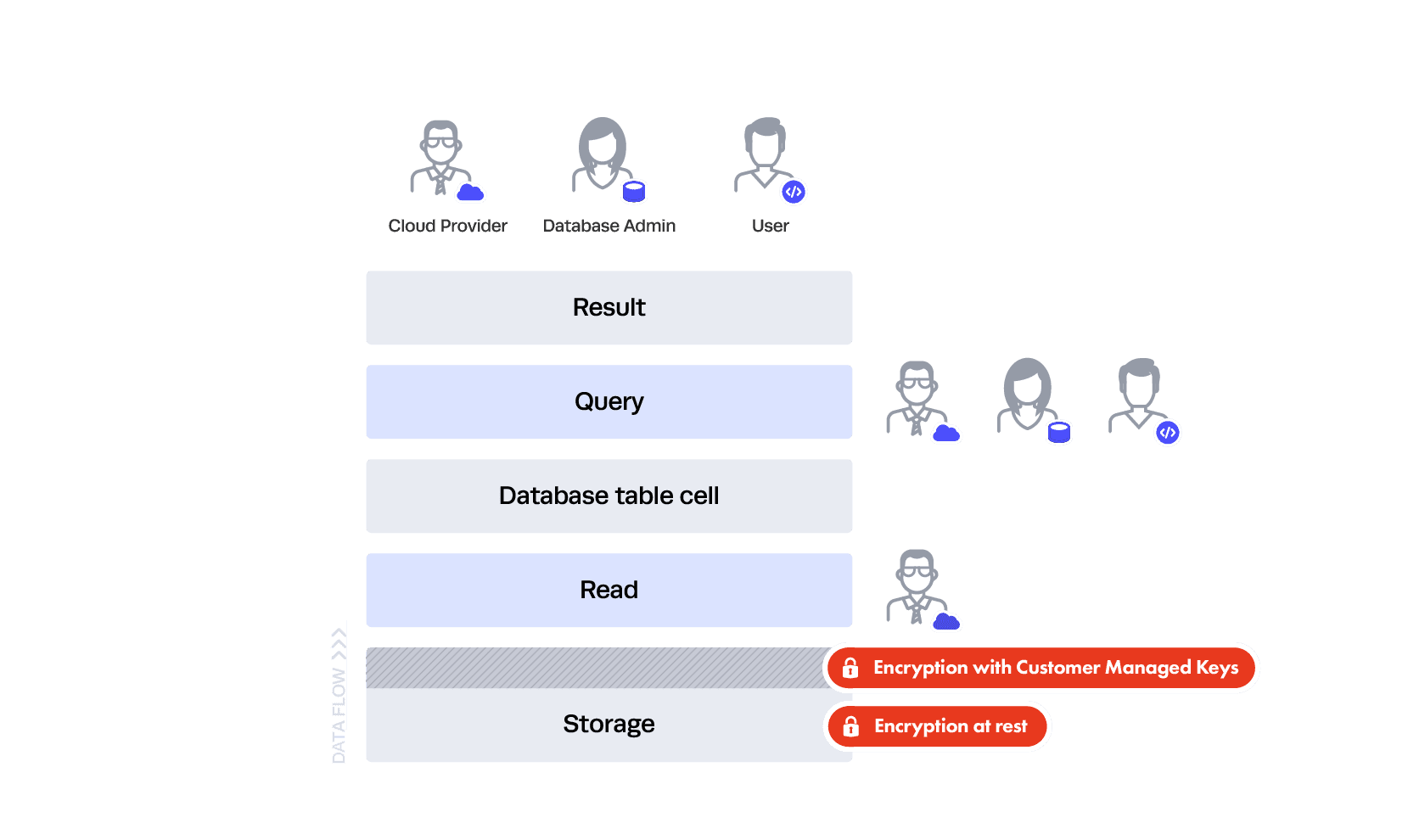
This gives you two layers of Transparent Encryption: one at the cloud service layer and another at the Snowflake data access control level, where every file holding your information is uniquely encrypted. But in that case, how do the database queries work?
It’s similar to how your laptop works — in the read interface between your queries and the data, the data is all “in the clear” as far as the query is concerned. This is akin to how you encrypt your laptop’s storage — you don’t see a file being decrypted for you to read in that specific interface each time you open it, but that’s exactly what’s happening behind the scenes. This is why you still see everything in a table even if it’s encrypted at rest.
So, how is this protecting you? If you configure everything well, users at the hardware level can’t see the data — just like someone who steals your encrypted laptop hard drive but doesn’t have your password. Since Snowflake is also encrypting all the files, you’re secondarily protected from the cloud service provider staff as a whole with “customer managed keys” technology.
That’s as far as you can go at the lower layers — anything further requires shifting trust elsewhere. This brings us to the fun part.
You don’t want everyone to be able to query every table. To ensure this doesn’t happen, you now have your DBA place table-level controls restricting who can query what tables, resulting in this image:
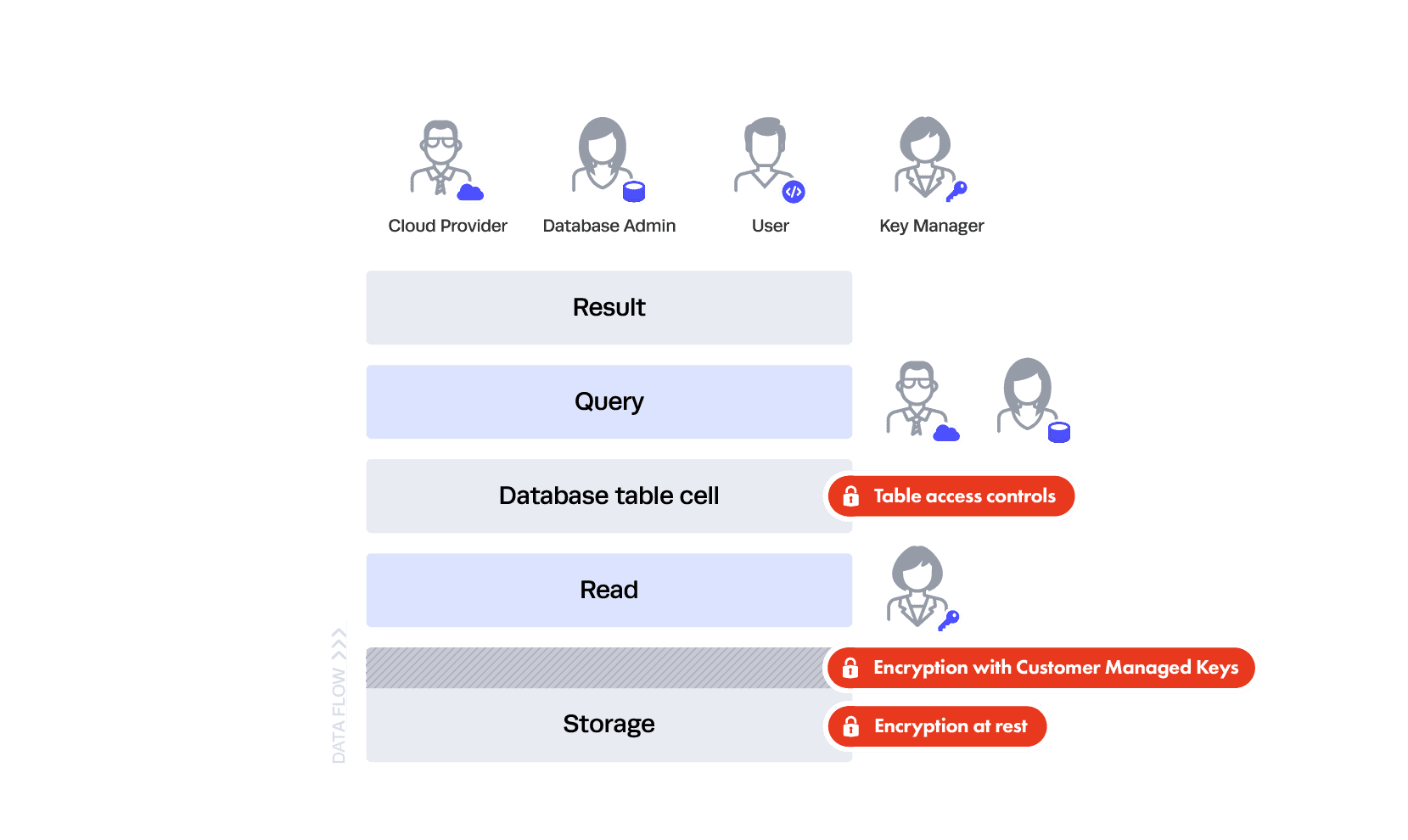
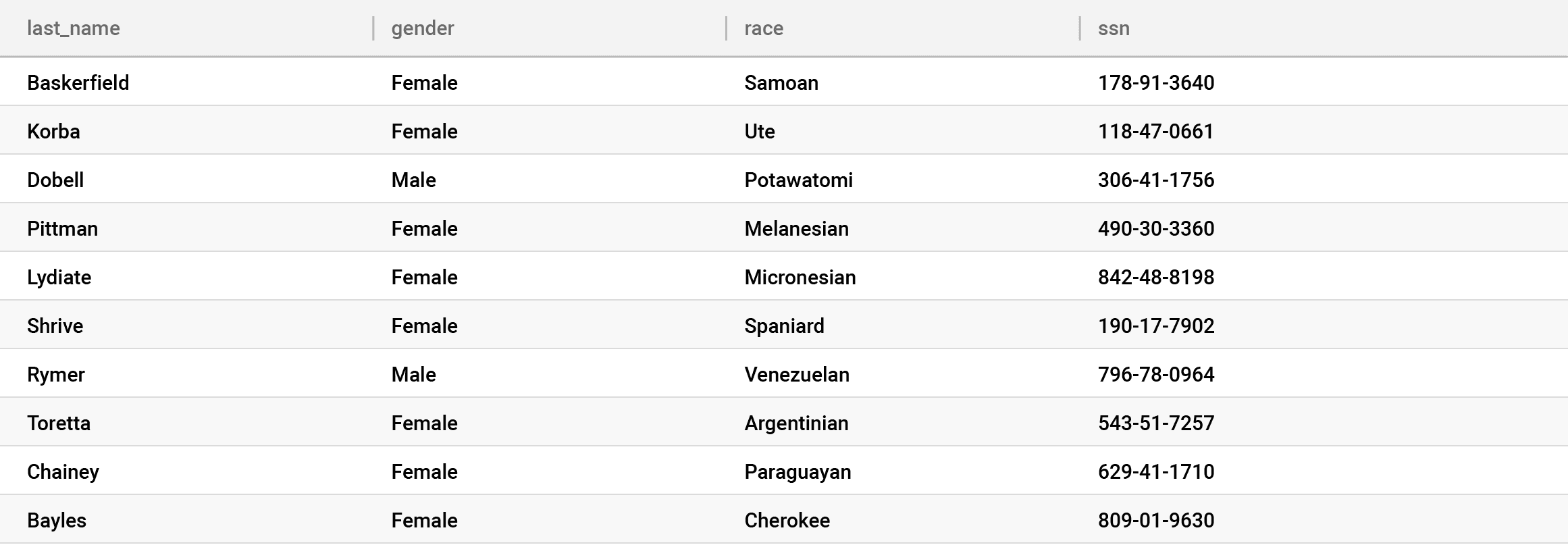
Now your users can’t query any table they want, whenever they want. The table above is still in the clear, but only to certain people. With Snowflake data governance, this uses the same familiar access controls most every data platform uses and is enforced in SQL. For example, your DBA would be able to see it along with the users that were entitled to see it.
We’ve set the foundation for very basic security, but with several remaining holes. Now, let’s explore how you can create the appropriate mix of security and privacy.
This is where things start to get tricky and we refer back to our different categories of privacy. A common idea for maximum protection is: “Let’s encrypt all the data in the database like we did in storage and I’ll control the key!”
Encrypting or tokenizing data before it lands in the database is commonly termed “encrypted on-ingest.” This would mean you encrypted data you are indexing in the Snowflake database before it ever landed in storage — and yes, that means it’s encrypted twice in storage, so when it’s decrypted out of storage through the aforementioned interface, it’s technically still encrypted because encryption was done on ingest. If you take this approach, only the person managing that encryption needs to be trusted.
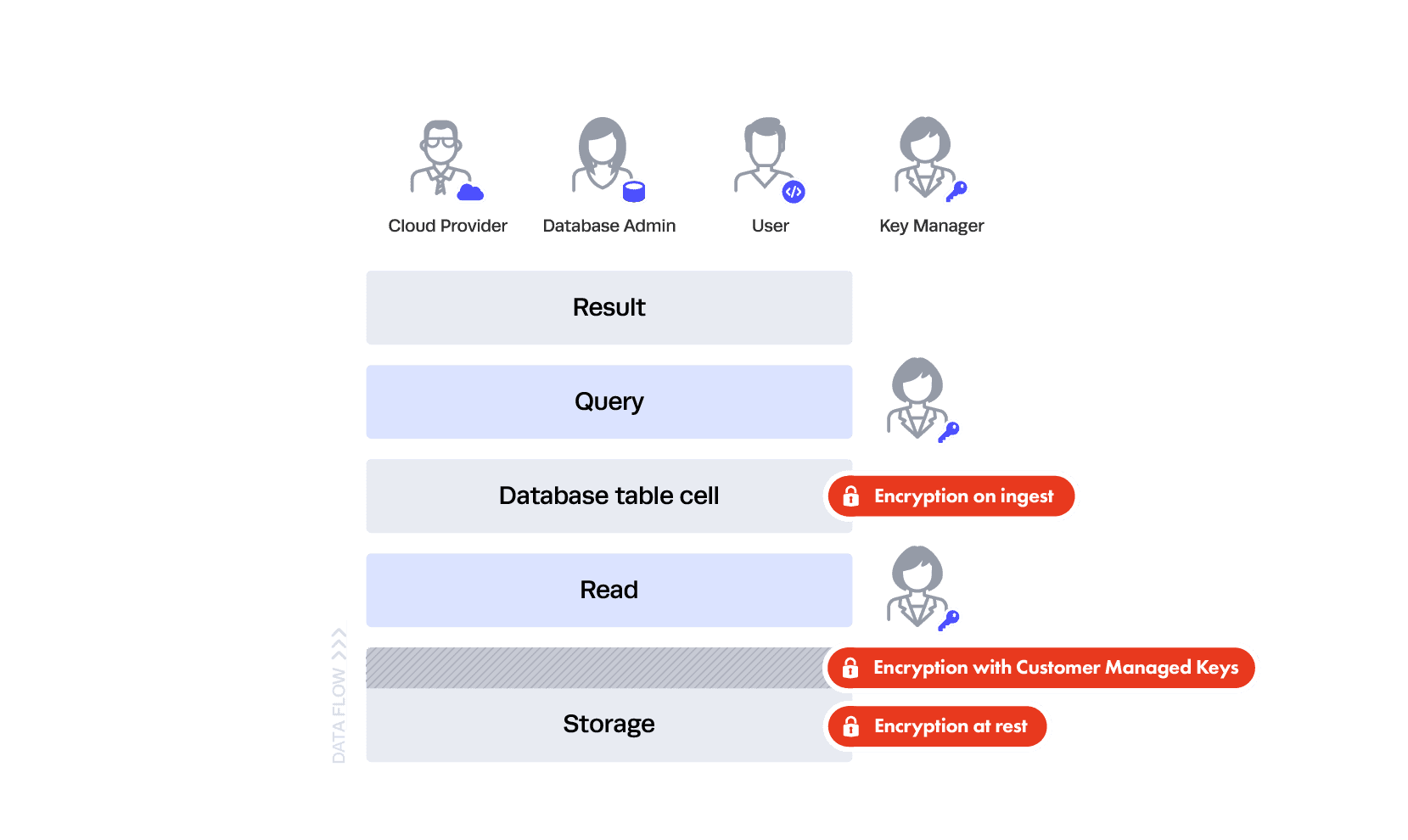
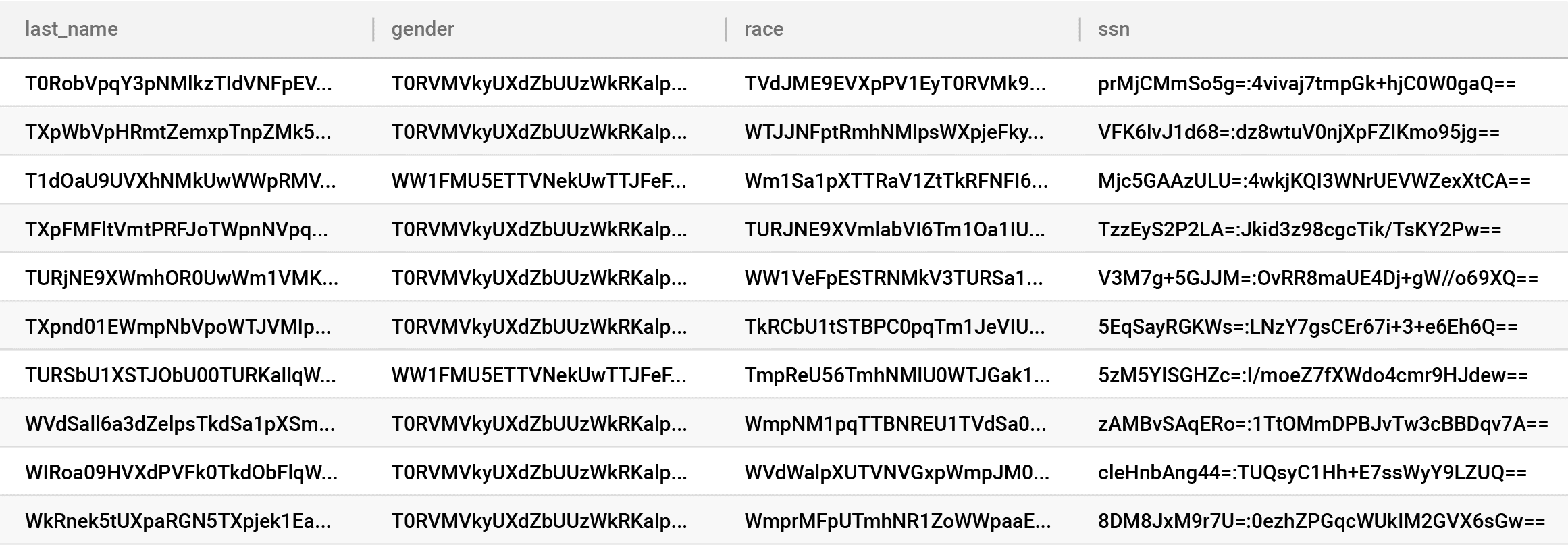
To be clear, this is a terrible idea.
Why? You just made your database completely worthless because everything is indexed by the encrypted value, as shown in the above table. Looking at an even simpler example, this would mean you turned this row in your database:
name: Steve
credit_card_number: 123456789
age: 44
address: 8787 Diamondback Drive, College Park MDinto this:
name: 3098jgp9iwr9iewgp9rweifg9e
credit_card_number: 09q3jepf3q0e8fefg8
age: 09q34ejtgpe9rgpiofjopssd
address: 09q34peigpe9irfdinsifvodsSo now when you run a query, your database doesn’t have the same fancy interface you had between your storage layer, and you won’t get any results back.
SELECT * FROM table_x WHERE name = ‘Steve’..nothing…
SELECT * FROM table_x WHERE age > 40…breaks — you just tried to query a text column with a numeric operation and the column had to be converted to text in order to encrypt it.
But what if you tokenize the data?
It’s the same problem — you are just replacing the garbled encrypted values with similarly useless (albeit more visually pleasing) fake values that also can’t be queried in a meaningful way. The only thing this solves is the column type problem.
So, what if you add a fancy interface that knows how to decrypt on the fly, like we have with the storage layer!? You can certainly take this approach, but doing so only solves a small piece of the problem. This is because the read from storage is “dumb” — it just needs to read blobs of data and have the interface decrypt them.
The interface between the database and data must be “smart.” It needs to only pull relevant data from its index based on a query. So the problem is that all the indexes are still based on the encrypted values. To make this work:
SELECT * FROM table_x WHERE name = ‘Steve’the interface must convert the ‘Steve’ into the encrypted value and push that down to the database so it can find the encrypted version of Steve, like this:
SELECT * FROM table_x WHERE name = ‘3098jgp9iwr9iewgp9rweifg9e’Voila! You get results, and they can be decrypted on read:
name: Steve
credit_card_number: 123456789
age: 44
address: 8787 Diamondback Drive, College Park MDThe problem is, this really only works well for equality (“=”) queries. … So what do you do in this scenario?
SELECT * FROM table_x WHERE age > 40The encryption does not take order into account, so this isn’t going to work. For example, 40 could get encrypted to xyz and 41 could get encrypted to abc. Tokenization will have the same issue. There are order-preserving encryption algorithms and other encryption algorithms that can support fuzzy search, but they are less secure. If you want to learn more about them, check out this paper from MIT CSAIL.
So where does this leave you? You should encrypt on ingest sparingly or not at all. If you choose to do it sparingly, that is where the privacy categories come into play. Encryption on ingest should be done against your most risky data, typically direct identifiers — essentially anything that must be hidden at all cost from your DBA and cloud provider. This also happens to be the category of data with the least utility, meaning people won’t be querying it often — and if they are, it will be equality queries — or using it for analysis. Real analysis is reserved for the juicy categories, like indirect identifiers and sensitive data. Here’s the latest picture:
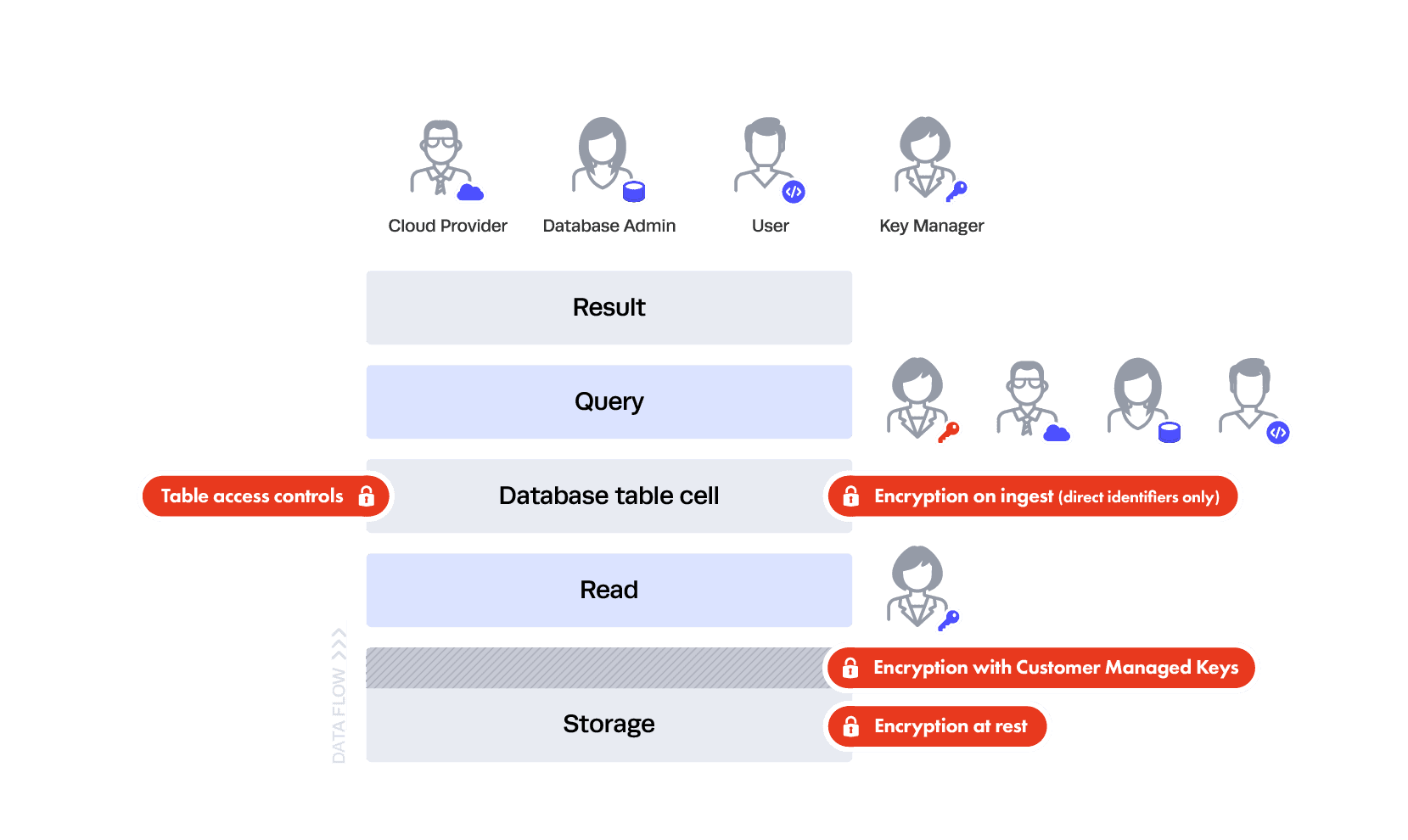
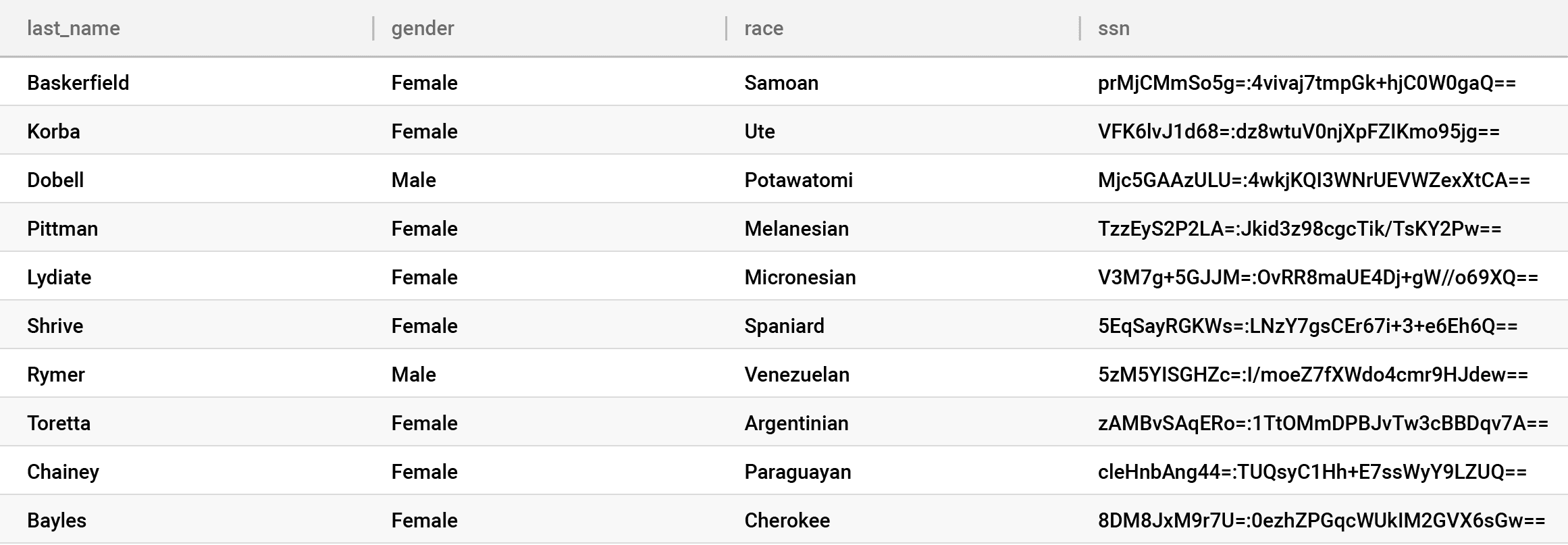
As you can see here, everyone can see some of the data — the indirect identifiers and sensitive data — and we still have table controls put in place by the DBA. But only the Key Manager can see all of the data — in this case, everything plus the SSN column. This is good because neither your DBA nor your Cloud Database Provider can see the encrypted, highly sensitive direct identifier (SSN), and if a data breach occurs, the attacker will only see the encrypted direct identifiers. Unfortunately, this still isn’t foolproof because someone could breach your key management system and see the data — it all depends on where the breach occurs in your trust layers because the trust was pushed elsewhere.
At this point, you still have indirect identifiers that are completely visible to users. Now you’ve come full circle to privacy controls. Many times, a solution to privacy controls is to create multiple versions of the same table, where different columns are missing so that you can share them as needed through your table controls. But this isn’t good enough. If you think back to the Netflix example, the movie ratings were both the attack failure point and the primary feature being used for the analysis. This cannot be a binary “yes or no” control.
This is where anonymization techniques can be applied. These are algorithms you can use to “fuzz” the data in such a way that it retains some level of utility but also provides a level of privacy, commonly termed privacy-enhancing technologies (PETs). One such PET is k-anonymization, which ensures there is no indirect identifier value revealed to the analyst/user that is unique enough to open the direct identifier(s) to a linkage attack. PETs can be applied through data copies as well, as we discussed with hiding columns. But doing that will result in static copies of data. Instead, you can use your fancy new trick — instead of decrypting-on-the-fly, you fuzz-on-the-fly.
This allows you to query the underlying data in meaningful ways — remember, that can’t be done when it’s simply encrypted — and also utilize the results in valuable ways for analysis. You are getting value from the data, while at the same time maintaining privacy. These techniques can be applied at query time to both indirect identifiers and sensitive data.
Why apply them at query time? As the amount of different privacy views into your data increases, it becomes an extract-transform-load (ETL) and role management nightmare to do this with table/data copies. It must be dynamic through the interface. Here’s that image:
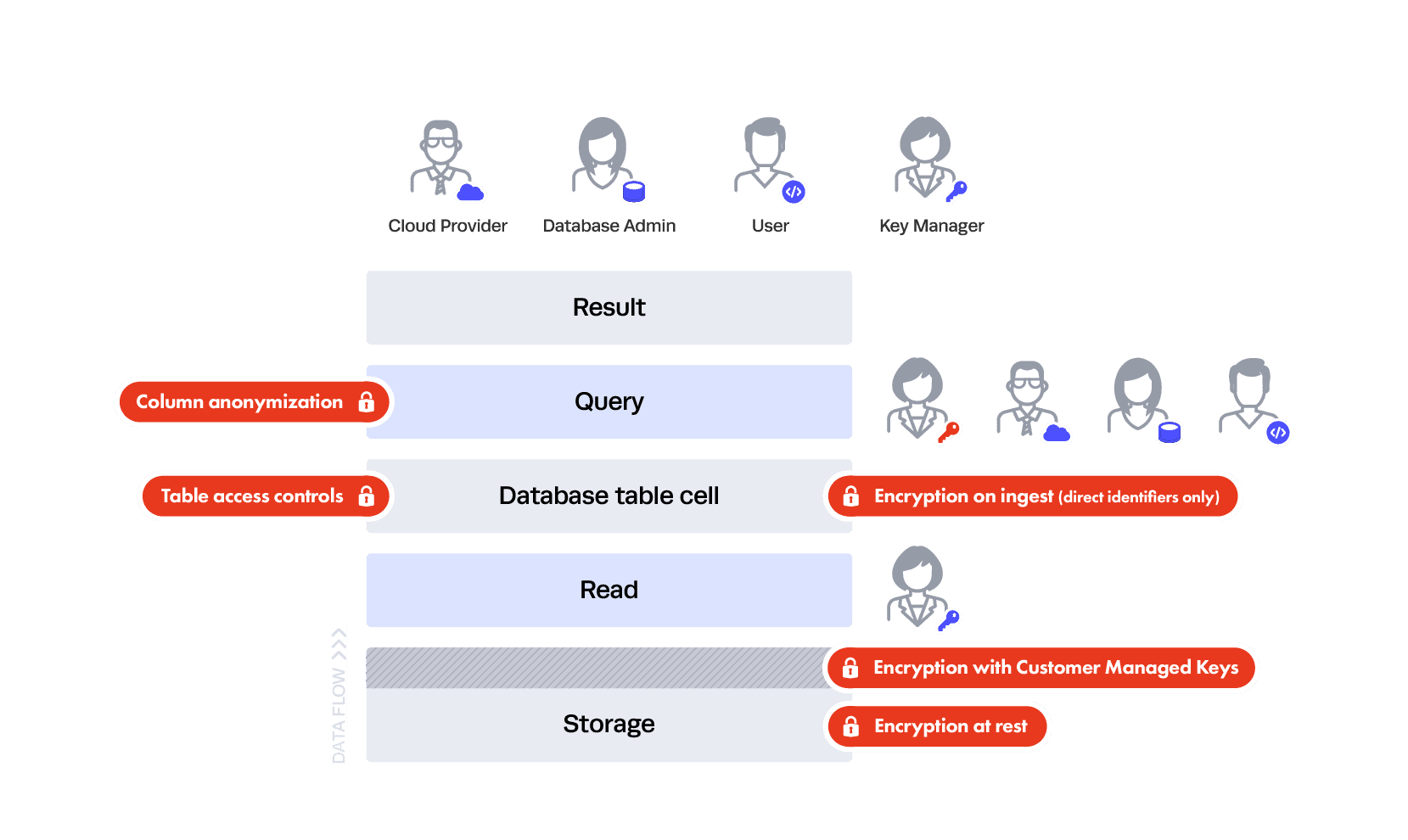
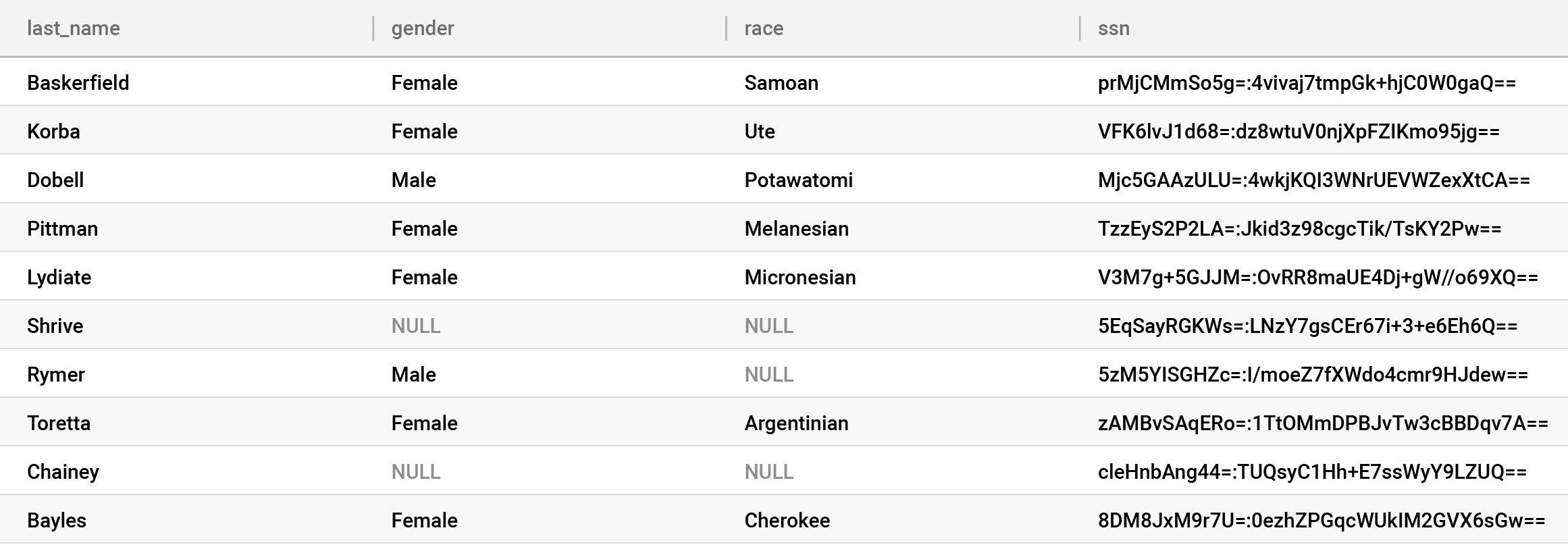
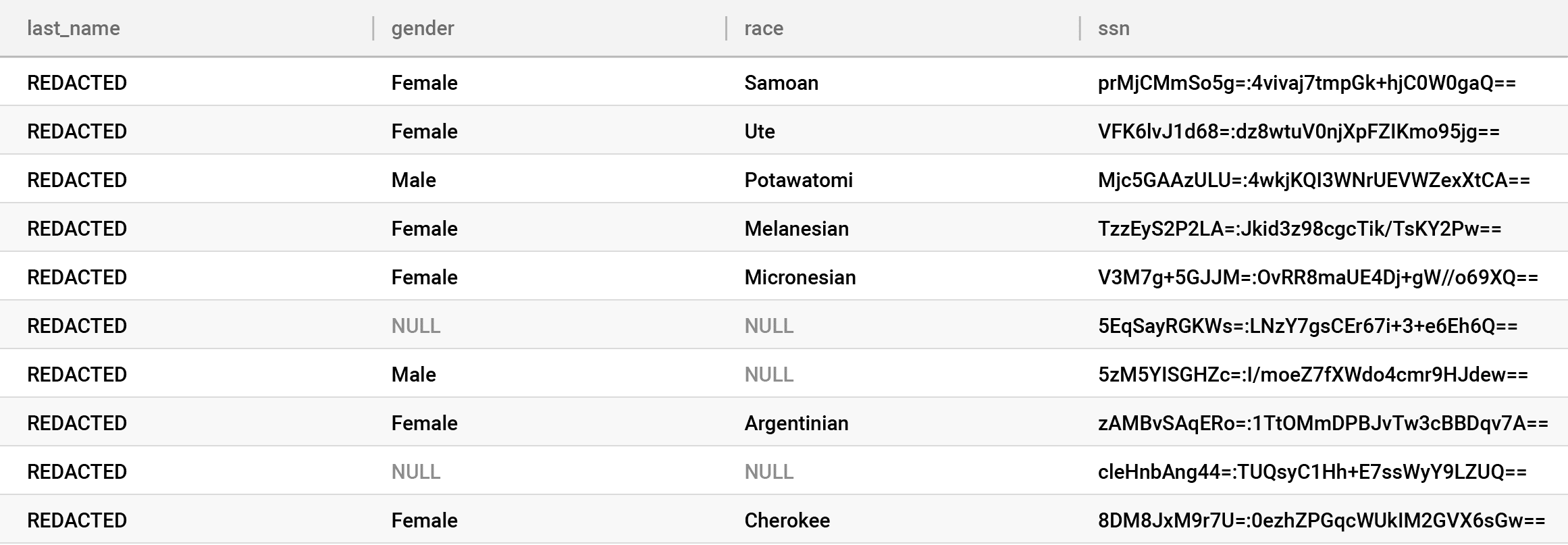
Look closely at the gender and race columns, to which we’ve applied the k-anonymization policy. This suppressed highly unique values — either in combination or by themselves — that could lead to a privacy breach with NULLs. But we left the other values in the clear, providing a high level of utility from these columns, rather than completely removing them. Immuta offers a wide variety of PETs, like k-anonymization, which allow customers to make tradeoffs between privacy and utility — fuzz – instead of block.
Additionally, Immuta provides an attribute-based access control (ABAC) model rather than a role-based access control model (RBAC). The key difference with ABAC is that complex and completely independent rules can evaluate many different user attributes, rather than conflating WHO and WHAT they have access to in a role.
As described by the NIST Guide to Attribute-Based Access Control (ABAC) Definition and Considerations: at access-request-time, “the ABAC engine can make an access control decision based on the assigned attributes of the requester, the assigned attributes of the object, environment conditions, and a set of policies that are specified in terms of those attributes and conditions. Under this arrangement policies can be created and managed without direct reference to potentially numerous users and objects, and users and objects can be provisioned without reference to policy.“
ABAC allows flexibility and scalability when building and enforcing policies, helping to avoid the “role explosion” required to cover all column access and anonymization scenarios when using RBAC. Immuta enables ABAC-based dynamic enforcement natively in Snowflake, without needing to manage Snowflake roles for your data analysts.
This delivers the full solution. You get all the pieces with the right type of data access controls:
And yes, it is possible to not encrypt anything on-ingest and instead manage all controls in the dynamic masking interface. To do this, there are algorithms to completely obfuscate values rather than fuzz them. This provides much more flexibility and functionality. If you take this approach, remember that some extra trust then lies with the cloud provider and your DBA for your direct identifiers, rather than the Key Manager. For example, we’ve redacted last_name on the fly in our table:
You are now at the intersection of security and privacy and meeting the demand of both your data analysts and your legal and compliance teams.
This is where Immuta comes in. Immuta can act as that interface between your queries and the database to execute dynamic masking and decryption. Below is a diagram of how it works:
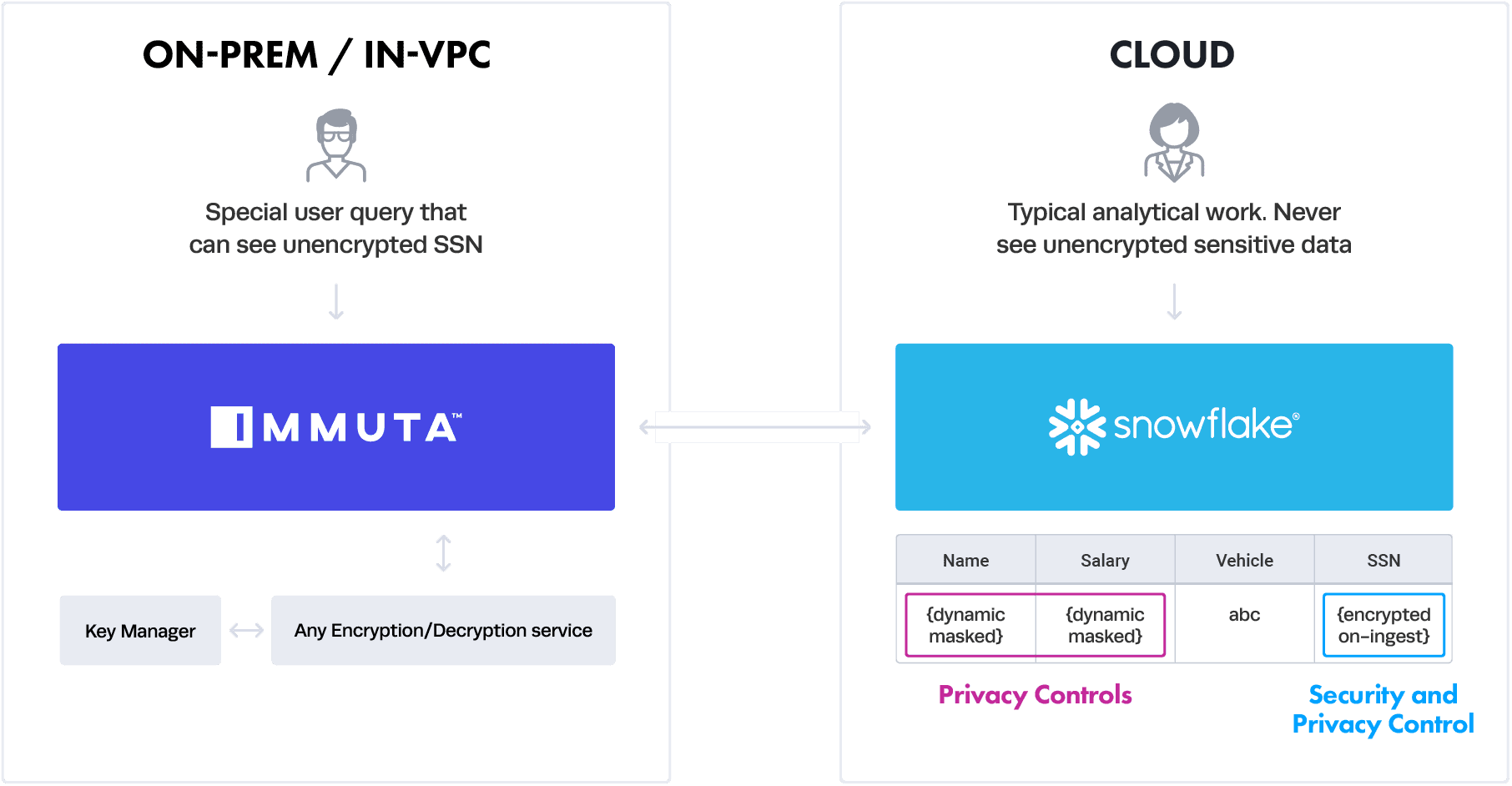
The typical analytical user on the right is querying the data as usual from Snowflake and the Immuta interface is dynamically masking the data with privacy controls based on policy. This is all done natively in Snowflake, with no proxy needed. In other words, this encrypt-on-the-fly and fuzz-on-the-fly approach means Immuta leverages built-in Snowflake features to ensure maximum flexibility and compatibility. The encrypted SSN can never be decrypted natively in Snowflake.
However, should a user with special access need to see the SSN column decrypted, they can leave native Snowflake and query through the Immuta proxy, which lives on-premises. In this case, that interface — the proxy — is able to decrypt the data using a customer-provided encryption/decryption algorithm service. This can talk to their own key management service — the details of which are completely abstracted from Immuta. Note this on-premises proxy can also achieve the dynamic masking and can support any other database — on-premises or across cloud data platforms.


