451 Research Reveals Data Supply Chain Gaps
Learn how to optimize your organization’s data supply chain to gain a competitive advantage.


We’re all familiar with supply chains in the realm of manufacturing. Well, the same concept applies to data management. In data management, there are data supply chains that involve raw inputs from source data systems that go through a number of processing steps and emerge at the end as a finished “data product.”
In this blog we define what modern data supply chains are and look at new research that can help you and your organization improve your data supply chain efficiency so you can get more value from your data.
A supply chain is broadly defined as the processes involved in producing and distributing a product or service, including the organizations, people, tools, and information necessary to get an entity into consumers’ hands.
The data supply chain narrows this definition slightly. According to S&P Global’s 451 Research, “the data supply chain represents the technological steps and human-involved processes supporting the flow of data through the organization, from its raw state, through transformation and integration, all the way through to the point of consumption or analysis.” By this definition, the data supply chain comprises three distinct data phases: raw data; transformation and integration; and consumption and analysis.
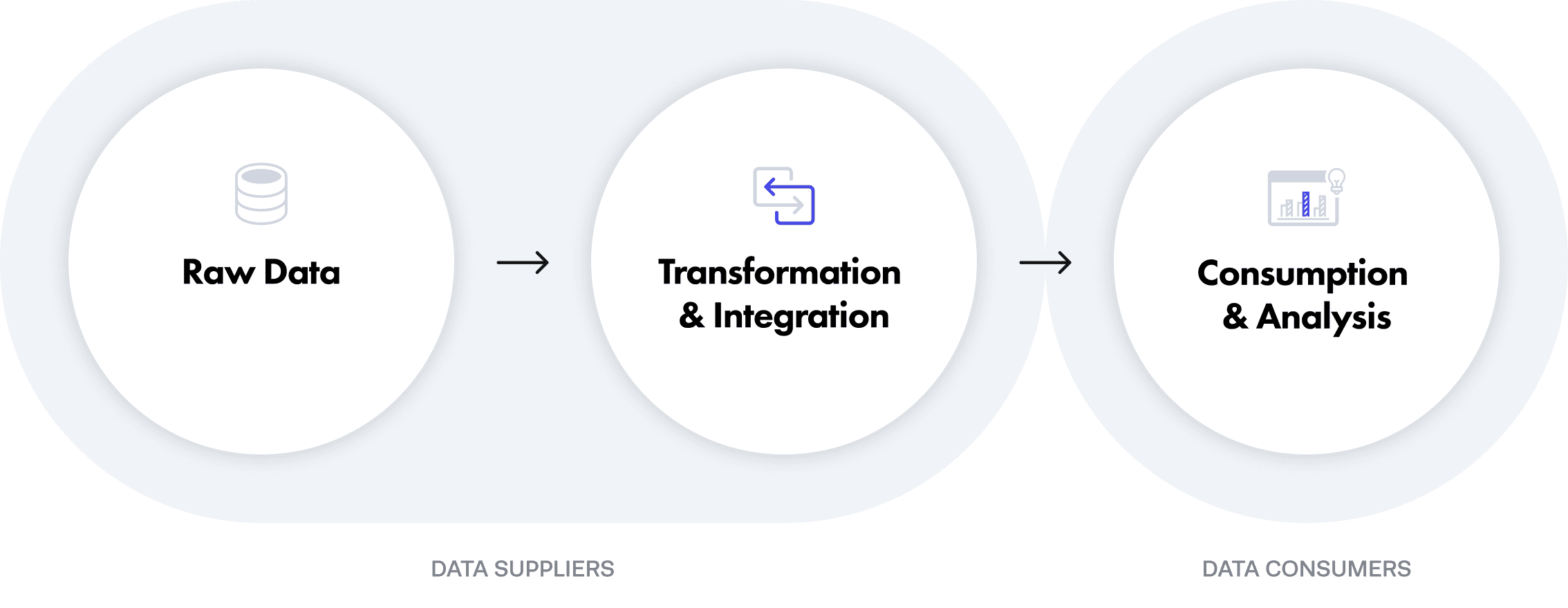
The people responsible for moving data through the supply chain fall into two general categories: data suppliers and data consumers. For purposes of this article, data suppliers are the people and tools within an organization that prepare data for use by data consumers. Data engineers, data architects, data stewards, and governance teams are all considered data suppliers, while data scientists, data analysts, and business intelligence teams fall into the data consumer category. However, these titles are generalizations and are apt to vary by organization.
35,000 data professionals receive our monthly newsletter to stay up to date on the latest insights, best practices, resources, and more.
As mentioned above, at a high level data suppliers prepare data for use by data consumers. But this broad definition just scratches the surface of what distinguishes the two groups.
Data suppliers are responsible for ensuring data consumers have a steady stream of relevant data to analyze for insights. Against the backdrop of a growing body of compliance laws and regulations, this means that the responsibility of preparing data in a way that is compliant with all applicable rules and regulations falls onto data suppliers. This need for secure access necessitates the use of privacy-enhancing technologies (PETs), such as dynamic data masking.
Data consumers, on the other hand, are responsible for making sense of data and deriving meaningful insights from it, which in turn drive organizational decisions. Direct queries, like SQL, are a common and well-known form of data consumption, but today’s data consumers also rely on self-service visualization, self-service data prep, data science tools and platforms, and internal data marketplaces to keep up with demand for data-driven insights.
According to S&P Global, 65% of survey respondents reported that data has become more important to their role today than it had been in the previous 24 months, and another 71% expect it to grow in importance to their organization’s decision-making.
Many companies have responded by hiring more data consumers, who can make sense of data and maximize its value for business-driving insights. In fact, 72% of respondents said that the number of data consumers in their organization is steadily increasing, and 73% anticipate that more human and machine resources will be needed to access and use data over the next 24 months. Clearly, the data consumption side of the supply chain has and will continue to be a focus for most organizations looking to make data-backed decisions.
However, investment in the data supply chain is off balance. While data consumption teams are well established in most data-driven organizations, there is still a dearth of data suppliers — and tools — to keep up with their needs.
The delta between data suppliers and consumers is most apparent when looking at each role’s top pain points. According to S&P Global’s data, 55% of all respondents — both data suppliers and consumers — said that data is stale or out-of-date when it arrives to them. However, when segmenting for just data consumers, that number jumps to 63%, indicating that outdated data is a more significant challenge for those responsible for analytics and insights.
It’s logical to assume that stale data is a downstream effect of inefficient data pipelines and slow processes — both of which, in theory, fall under the purview of data suppliers. As a result, data suppliers report outsized levels of frustration from data consumers who are hindered by the inability to access real-time data. Yet, exploring data suppliers’ top pain points reveals that they face systemic barriers to improving processes and optimizing data pipelines, and therefore do not deserve to fully bear responsibility for delayed time to data access.
The survey found that more than a third of data suppliers cited lack of personnel or skills as the biggest challenge faced in their job roles, followed closely by a lack of available automation to drive processes. This finding reiterates the earlier point that the data consumption side of the data supply chain benefits from more investment in human and machine resources than the data supply side.
Despite this imbalance, it’s worth noting that lack of automated technology creates pain felt on both sides; 37% of data consumers blamed lack of automation for technology-based bottlenecks — which inevitably cause stale data. It’s easy to see how intertwined these processes are, as well as how important data supply resources are to optimizing the entire data supply chain.
Learn how to optimize your organization’s data supply chain to gain a competitive advantage.
Efficient data analytics and data initiatives are contingent upon efficient data pipelines. The rise of DataOps has made agile processes and two-way flows of data between data suppliers and data consumers more important than ever. Simply put, to compete with data now and in the future, organizations must invest in both sides of the data supply chain — with a particularly keen focus on the historically under-resourced supply side.
Data suppliers require not just human resources, in the form of data architects and data engineers, but also automated tools that enable seamless data security without time consuming, labor intensive processes.
As organizations move to adopt cloud-based, automated data management tools for analytics and data science, it is important to consider the impact on the data supply chain. How disruptive is the new tool? How much training and maintenance is required? How automated is it? Without careful planning, some new tools can become more of a burden on existing data supply chains than they are worth.
We built Immuta with the modern data supply chain in mind, ensuring that Immuta fits seamlessly into any cloud architecture. Immuta allows data suppliers to enforce sensitive data discovery, data access control, and data monitoring across heterogeneous cloud environments, and use dynamic attribute-based access control to easily scale user adoption. Data engineering and operations teams no longer need to rely on manual process, and are able to use automated policy enforcement so data consumption can happen in real-time, without risking data security and privacy.
As we move into this new era of data, building fast and efficient data supply chains will be the most effective way to keep up with data demand and maximize data’s value and business-driving impact.
To read all the results of S&P Global’s survey, download the report here.


