As organizations leverage growing amounts of data for business-driving insights, they are met with the fast-paced evolution of data compliance laws and regulations. According to a survey of 700+ data professionals, 70% of organizations are subject to 10 or more regulations.
This only underscores the necessity to understand the types of data you are collecting, that data’s level(s) of sensitivity, and how it is being used. Through consistent data discovery and classification, you can have a comprehensive understanding of your data and apply the required data security and privacy measures to maintain compliance.
In this article, we’ll discuss how automated data discovery helps to streamline this process and empower regulatory compliance.
What is Automated Data Discovery and How Does it Work?
Data discovery is the process of identifying and analyzing data from a variety of sources to uncover trends and patterns within that data. This process occurs early in the data use lifecycle, as new data sources are onboarded into existing cloud data ecosystems.
During onboarding, data discovery scans and tags data according to various classifiers, such as personally identifiable information (PII), protected health information (PHI), or other sensitive identifiers, as shown below in the Immuta UI.
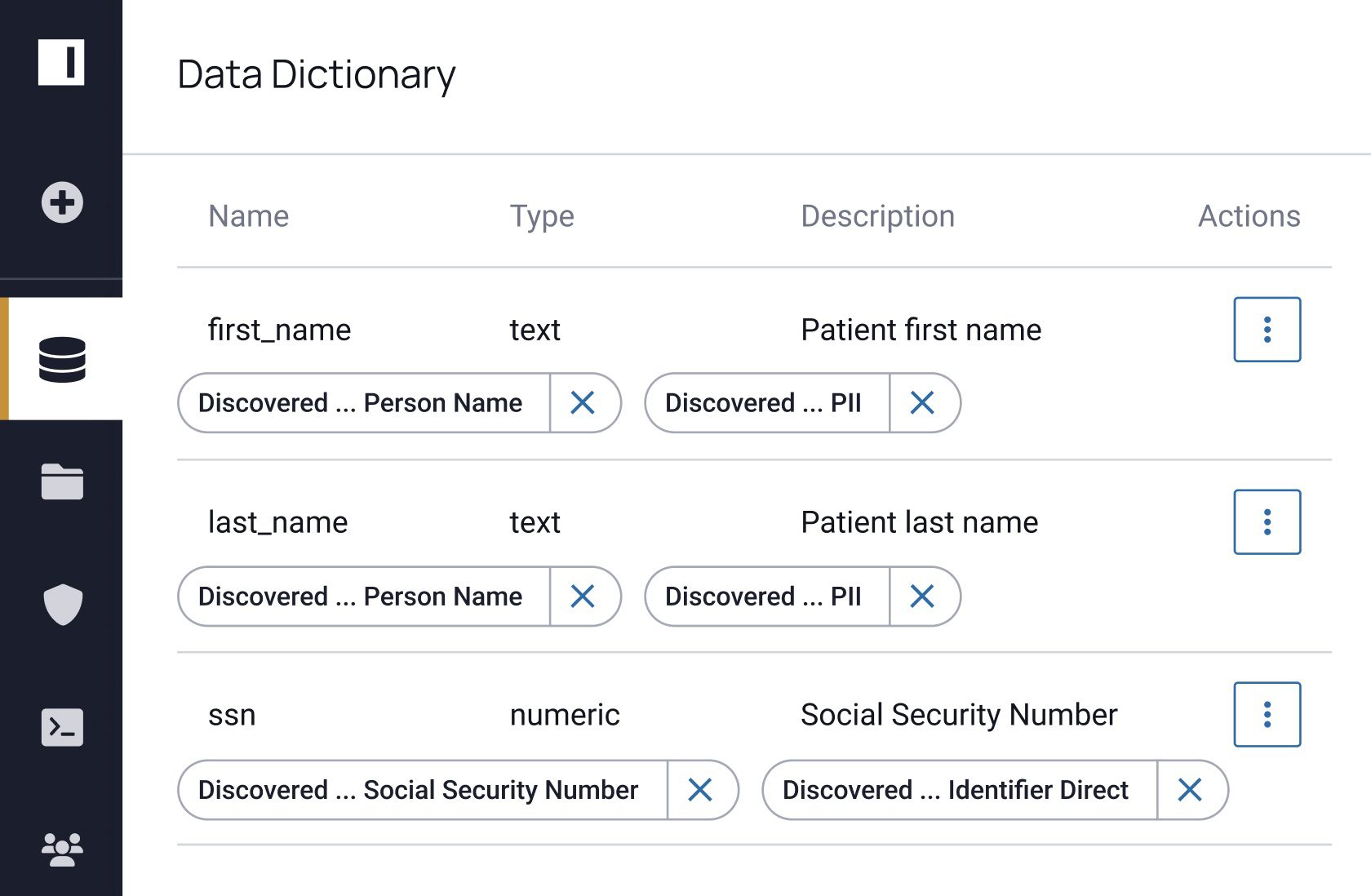
This data can also be scanned in the context of regulatory frameworks.
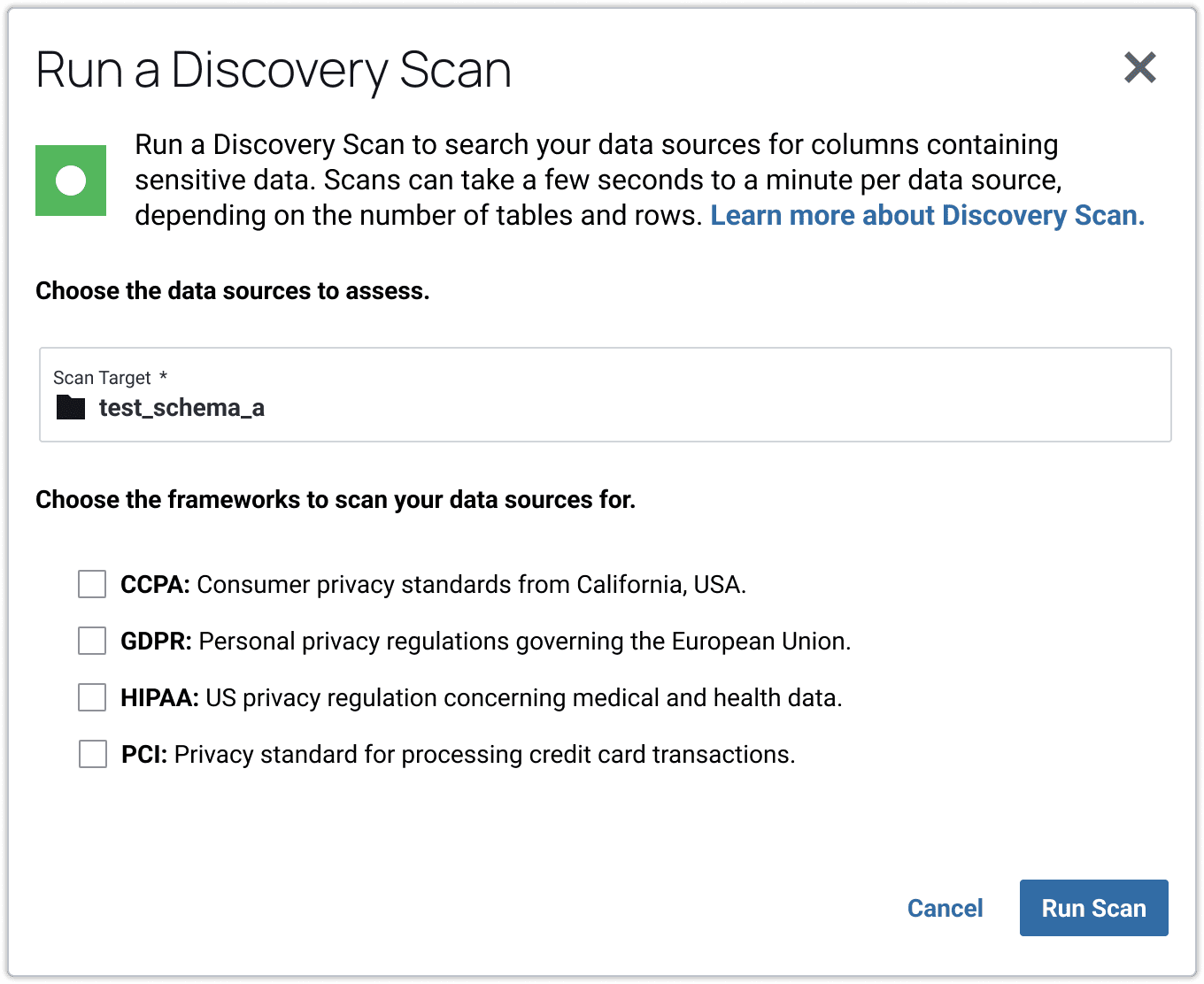
Once sensitive data is discovered and identified, teams can create policies to enable data access control and security. Methods like dynamic attribute-based access control reference data’s classification type and sensitivity level in order to effectively control which users are able to access and use it.
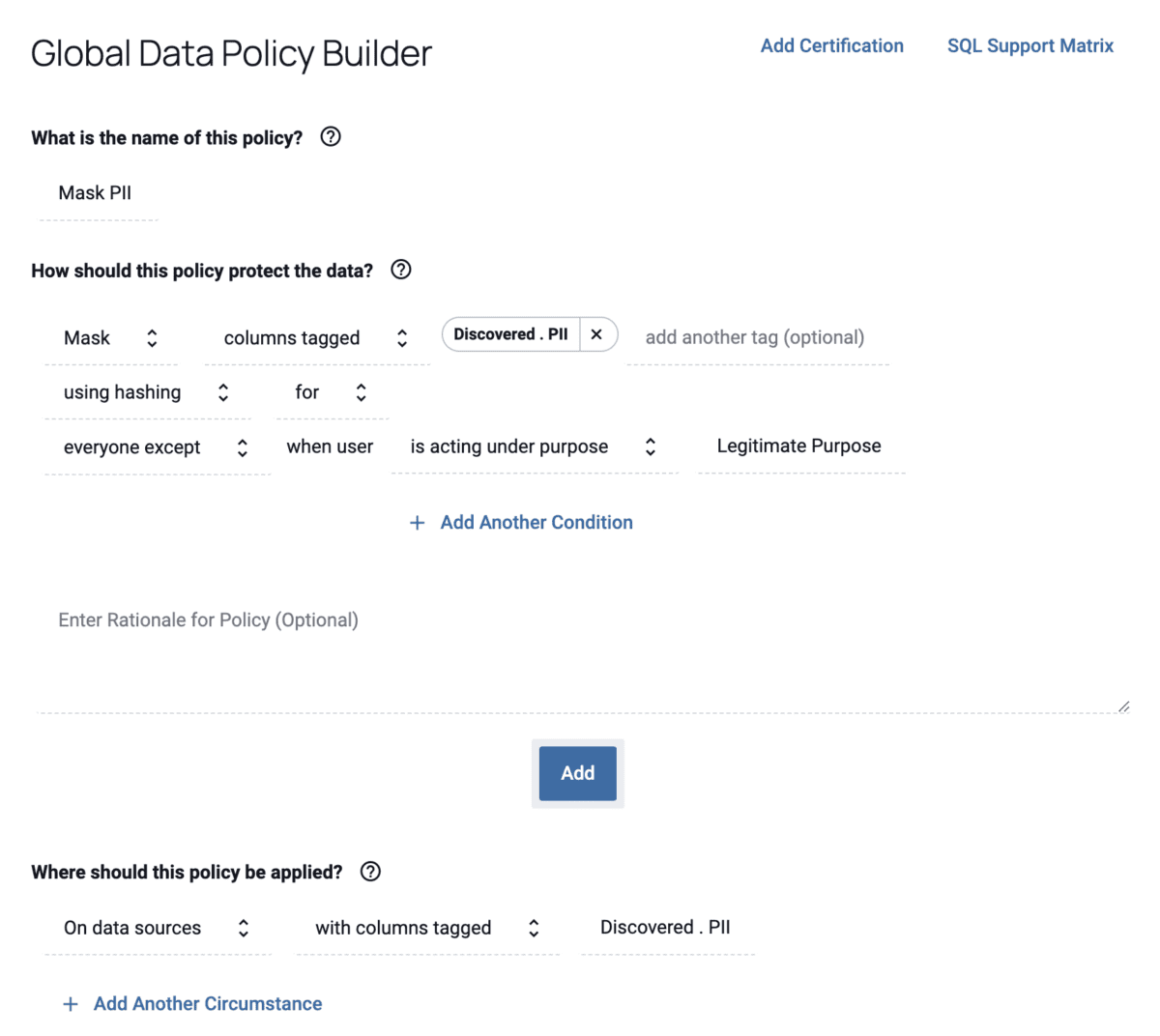
Automated data discovery takes this process and–you guessed it–automates it. This means that any data sources that are added to your environment will automatically be scanned and tagged according to your organization’s chosen classifiers, identifying them appropriately and making them ready for secure use across teams.
Why Should You Automate Data Discovery?
It is entirely possible for data discovery to be done manually. You can choose to review and tag each data source individually as you add them to your data ecosystem. This method is most feasible for organizations with limited data resources, use cases, and users.
The reality is that most modern organizations are focused on data-driven growth. According to survey research conducted by S&P Global, over half of data practitioner respondents (69%) said most or nearly all of their organizations’ decisions are driven by data. This demonstrates the increasing value of data for businesses, and indicates that data use is growing too quickly to justify manual discovery.
Automated data discovery empowers you to grow your data sources and use cases without adding undue security and noncompliance risks. By automating this process, you can ensure that all data is scanned and tagged immediately as it enters the ecosystem. This eliminates the burden on your team to tediously review every single data source, and instead opens you up to greater efficiency and scalability.
The Impact of Automated Data Discovery
When automating the data discovery process, you can expect a range of benefits for your data teams, business initiatives, and compliance needs. These include:
Cross-Platform Consistency
The modern data stack is complex, often including an array of platforms and tools. As data moves between them, it needs to be consistently secured against threats and potential misuse. This requires a holistic understanding of the types of data that exist throughout the ecosystem.
Let’s say your organization uses both the Databricks Lakehouse platform and the Snowflake Data Cloud. Using manual data discovery and classification, you would need to apply tags separately in Databricks and Snowflake, then check to ensure those tags – and corresponding policies – match up across platforms, so as to avoid any gaps. Not only would this take a substantial amount of time, but it’s a highly error-prone approach.
Using a dedicated automated data discovery tool that integrates across the platforms in your tech stack, you can mitigate these pitfalls and confidently understand the types of data within your ecosystem. By ensuring that standardized discovery and tagging occur before the data is even stored in your platforms, you can achieve consistency with much greater efficiency.
Simplified Risk Assessment and Prevention
Any organization that leverages data almost certainly possesses sensitive data, such as demographic, health, or financial information. This data must be handled delicately, but without visibility into what sensitive data you have, it’s impossible to adequately protect it.
Let’s say you run a join query on two different tables. However, when sensitive data from one table is combined with sensitive data in the other table, it reveals personal information about an individual in your database. Not only would this violate data privacy regulations, it would also expose personal information to unauthorized users.
Automated discovery and classification provides a complete overview of your data types and levels of sensitivity. This lets you understand your sensitive data footprint and put the necessary controls in place to ensure that, even when combined, data is properly protected against unauthorized access. Additionally, this gives you insight into your organization’s cyber threat landscape and other relevant risks. These factors, in turn, will inform the security and privacy measures you implement to guarantee the right level of sensitive data protection.
Streamlined and Holistic Compliance
Keeping up with regulatory requirements is already a complicated enough task – one which automated data discovery significantly helps streamline. These regulations often impact how data is collected, stored, accessed, and used, and are implemented to protect sensitive information from breaches, leaks, or general misuse.
As mentioned before, security and privacy policies must take into account both the attributes of the data they protect and the users accessing it. Manual discovery and tagging requires administrators to have a complete understanding of every regulation that applies to their data sources.
When discovery is automated, specific regulation-based tags and classifiers can be applied to data that, in turn, facilitate the creation and application of compliant access policies. For example, a data localization law might impact data that is generated in a specific country or region. Taking this law into account, you can add a tag that identifies if data is from that region, and have the right policy applied automatically.
Improved Data Security Posture Management
As data resources and ecosystems grow, organizations are placing a larger emphasis on data security posture management (DSPM). This process aims to proactively secure sensitive data where it lives in a data ecosystem by automating data discovery, classification, monitoring, detection, and protection tasks. A manual approach to DSPM would be slower and subject to human error, which would almost certainly result in reactive responses to data threats.
DSPM is an ongoing process, subject to changing requirements, business objectives, risk appetites, and other factors that might impact data security. Automated data discovery informs DSPM efforts with crucial context about factors like data’s level sensitivity, location in the ecosystem, volume, and more. And while DSPM is subject to many moving parts, gaining a deeper understanding of data types and sensitivity through automated data discovery is a foundational part of the process.
Choosing an Automated Data Discovery Solution
Implementing automated data discovery is an integral step in growing your data-driven business without risking security or noncompliance. For a deeper dive into the factors that go into selecting the best tool for your organization, check out How to Choose a Data Discovery Solution.