2023 Data Access & Security Trendbook
Insights into the future of secure data use


As important as data analysis is to modern businesses, enforcing the proper access control on that data will always be paramount. This remains true as organizations in every industry continue migrating sensitive data to the cloud from legacy data storage systems.
Regardless of which tools and platforms are used for storage and compute purposes, controls that monitor and regulate data access must be in place. And while deep dives into access control modernization, high level data access control breakdowns, and comparative glances of contemporary access control methods can be helpful, sometimes it can be more informative to understand how these models operate in practice.
In this blog, we’ll examine the real-world impact of an organization’s data access control approach on data analytics efficiency, productivity, security, and overall operability. Through this example, we’ll see which access control method is untenable for modern use cases – and which will guide businesses into a scalable, secure, and sustainable future.
Regardless of industry, virtually all modern organizations collect, store, and analyze data in order to attain insights and drive success. This data can be generated during the course of business operations, gathered from customer interactions, or sourced through a variety of other means.
However, the ways in which this information is leveraged and repurposed varies by industry. For instance, those in the financial services (FS) industry might interact with data daily when receiving a forecasting report, viewing a predictive model of the market, or sharing financial data to foster improved data ecosystems. In the healthcare and life sciences industry, data is similarly prevalent in everyday practices. Appropriately sharing patient diagnosis information, examining customer insurance details to determine coverage, and other similar daily uses all require real-time access to relevant data.
One constant throughout these scenarios is the sensitivity of the information involved. Organizations frequently collect and store data that includes personally identifiable information (PII), personal health information (PHI), or other sensitive data. This PII and PHI can range from things like addresses, credit card information, and license numbers to biometric data, social security numbers, and medical records.When access to this data opens up to a wider range of data users, it is critical that access controls scale to ensure that sensitive information is not improperly used. If controls can’t maintain their effectiveness at scale, they put this data – and those that created it – at immense risk.
To examine how access controls can impact data’s security and efficacy, we’ll focus on the world of retail. For retailers, data provides an up-to-date view of inventories, customer experiences, shipment logistics, and other valuable information.
For our example, we’ll consider a weekly sales flash report at a retail grocery chain. A flash report is a short document that provides users with key data about financial performance, operational success, and progress towards key performance indicators (KPIs). To create such a report, a variety of organizational data must be gathered and condensed so that the necessary parties can view it on a regular basis.
We’ll assume that this chain operates on a 4-4-5 retail calendar, with roughly 13 weeks a quarter that will require a sales flash report. With 340 unique stores in this chain, and six distinctive data users per store, a total of 2,040 users chain-wide would require access to the data in this report. Each of these 2,040 users should be subject to access control policies, as it is both unlikely and unsafe that they’re authorized to access completely unfiltered sensitive data. So, how should this access be controlled efficiently?

Insights into the future of secure data use
First, let’s assume that your organization decides to take a role-based approach to access control policies. We’ve already determined that there would be a total of 2,040 data users across 340 unique stores who would require access to these weekly flash reports. With role-based access control, each of these users would require a unique role that is built based on both their user type (of which there are six per store) and their store ID (of the 340 total).
At a base level, this means whoever is in charge of data governance would be required to create and maintain at least 2,380 access policies to enable all users to query the flash report (2,040 users + 380 store IDs). On top of this, we can assume that the retailer will have an annual user attrition/advancement rate of roughly 20%. This introduces another 408 possible users that would require additional role-specific access policies, bringing the total number of policies up to 2,788.
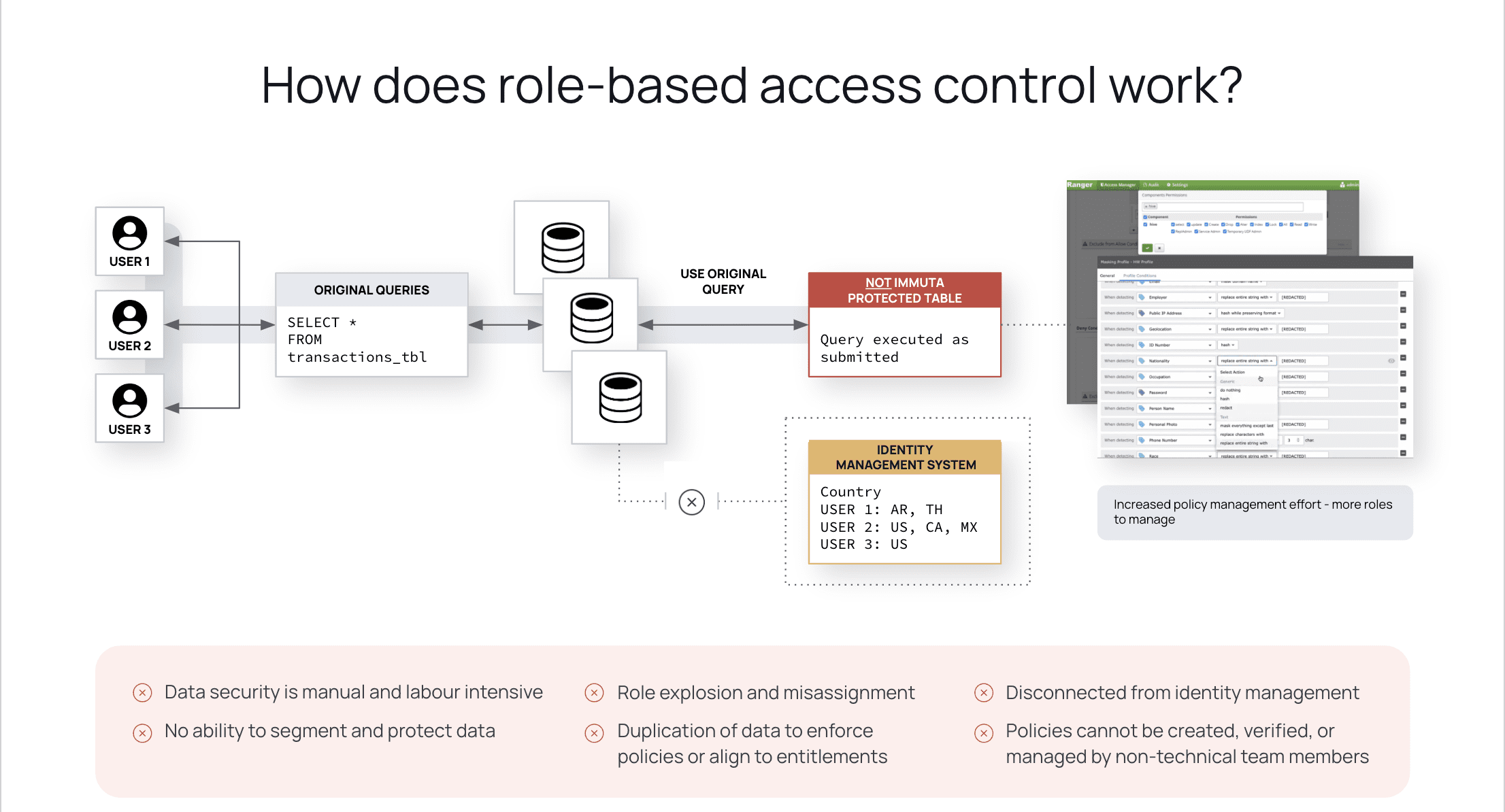
Why might this be an issue? Role-based policies, due to their static nature, must be individually created and maintained for each system user. These policies can also be quite technical in their implementation, requiring coding skills that most stakeholders will likely not possess. Beyond this, having to manually make changes to each role only increases the burden on data teams, leading to role-explosion, misassignment, and the inability to properly segment and protect sensitive data.
Now, let’s consider the same scenario with attribute-based access controls. Rather than requiring specific policies for each of the 2,040 retail data users, access can instead be determined based on applied user attributes. ABAC policies can also reference object and environmental attributes when determining data access.
Unlike the static role-based policies, attribute-based access controls do not need to be written and maintained for each individual user. These attributes only need to be assigned to users once in the data ecosystem, in our example based on the same matrices of User Role, Store ID, and Store Department. These attributes can be informed by existing metadata catalogs, making the process even more hands-off than assigning roles. While these aspects would require individual specification with RBAC, as assigned attributes they are examined and actively applied to each user who queries the flash report.
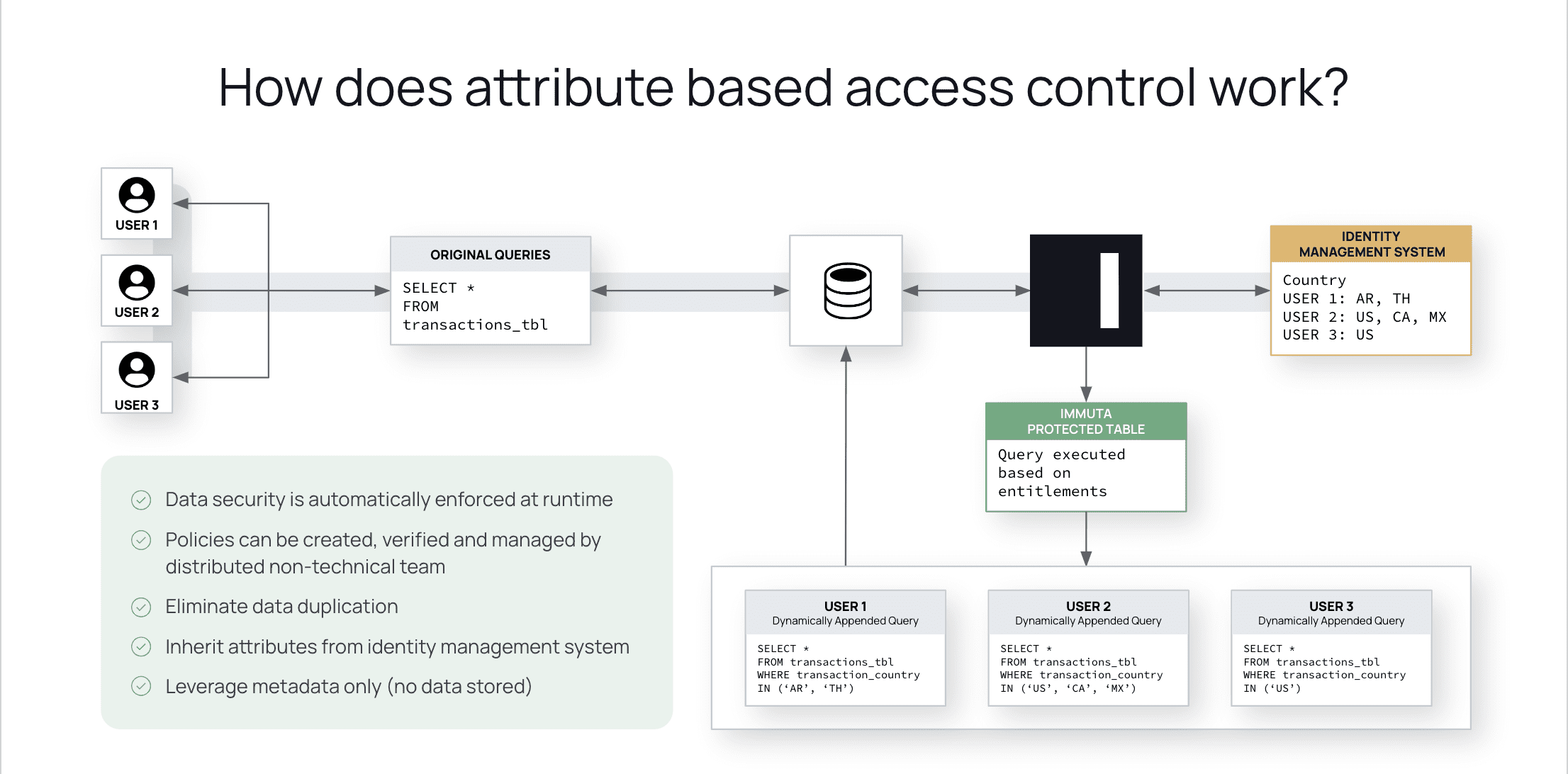
This eliminates the need for user-specific policies, and reduces the necessary access policies in our scenario from a possible 2,788 all the way down to 3. These policies will determine access at run-time based simply on whether or not the user possesses the required attributes. Written in plain language, they can be created and understood by a wider range of stakeholders, including legal and compliance teams, and can be updated once and applied at scale when necessary. This ensures that sensitive information is consistently protected, without inhibiting data users’ efficient access to the flash reports each week.
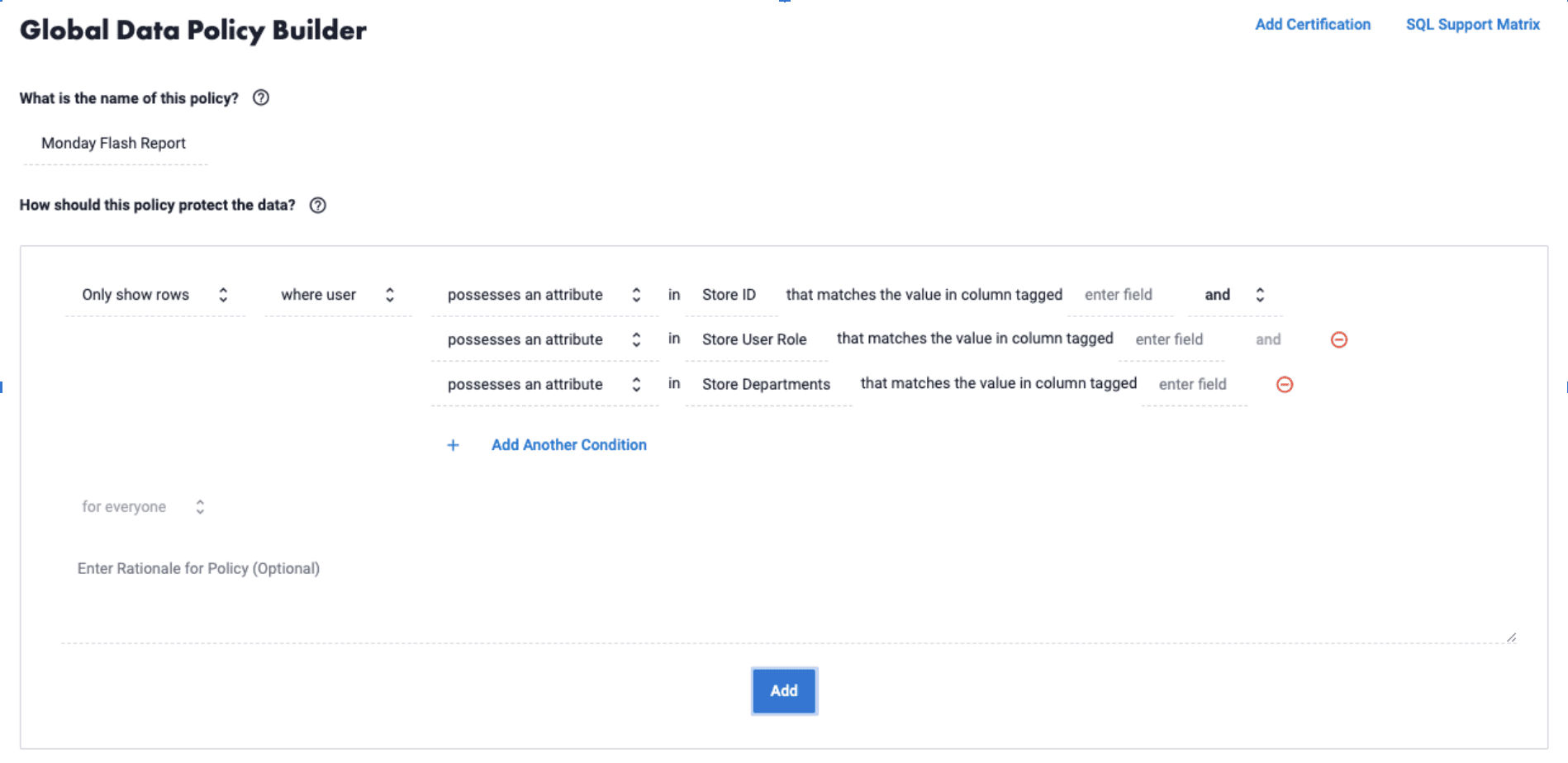
Through this retail flash sheet scenario, it is clear that attribute-based access control is the more effective model for delivering timely, efficient, and secure access to business-critical information.
Unsurprisingly, this scenario repeats across industries in a range of everyday use cases. In each of these examples, important data access functions can be made unnecessarily difficult through the implementation of outdated role-based access controls. By choosing a data access solution that leverages automated ABAC capabilities, you can achieve timely data access at scale. With a tool that dynamically discovers, secures, and monitors your organization’s data, access policies can be created and maintained with ease. This lessens the burden on data teams, and unlocks ease of access to a wider range of stakeholders – all without sacrificing security.
To try creating a policy in Immuta, check out our self-guided walkthrough demo today. For a deeper dive into the realm of access control, download our white paper RBAC vs. ABAC: Future-Proofing Access Control.


